 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiff-MN: Diffusion Parameterized MoE-NCDE for Continuous Time Series Generation with Irregular Observations
Jan 30, 2026Time series generation (TSG) is widely used across domains, yet most existing methods assume regular sampling and fixed output resolutions. These assumptions are often violated in practice, where observations are irregular and sparse, while downstream applications require continuous and high-resolution TS. Although Neural Controlled Differential Equation (NCDE) is promising for modeling irregular TS, it is constrained by a single dynamics function, tightly coupled optimization, and limited ability to adapt learned dynamics to newly generated samples from the generative model. We propose Diff-MN, a continuous TSG framework that enhances NCDE with a Mixture-of-Experts (MoE) dynamics function and a decoupled architectural design for dynamics-focused training. To further enable NCDE to generalize to newly generated samples, Diff-MN employs a diffusion model to parameterize the NCDE temporal dynamics parameters (MoE weights), i.e., jointly learn the distribution of TS data and MoE weights. This design allows sample-specific NCDE parameters to be generated for continuous TS generation. Experiments on ten public and synthetic datasets demonstrate that Diff-MN consistently outperforms strong baselines on both irregular-to-regular and irregular-to-continuous TSG tasks. The code is available at the link https://github.com/microsoft/TimeCraft/tree/main/Diff-MN.
OATS: Online Data Augmentation for Time Series Foundation Models
Jan 26, 2026Time Series Foundation Models (TSFMs) are a powerful paradigm for time series analysis and are often enhanced by synthetic data augmentation to improve the training data quality. Existing augmentation methods, however, typically rely on heuristics and static paradigms. Motivated by dynamic data optimization, which shows that the contribution of samples varies across training stages, we propose OATS (Online Data Augmentation for Time Series Foundation Models), a principled strategy that generates synthetic data tailored to different training steps. OATS leverages valuable training samples as principled guiding signals and dynamically generates high-quality synthetic data conditioned on them. We further design a diffusion-based framework to produce realistic time series and introduce an explore-exploit mechanism to balance efficiency and effectiveness. Experiments on TSFMs demonstrate that OATS consistently outperforms regular training and yields substantial performance gains over static data augmentation baselines across six validation datasets and two TSFM architectures. The code is available at the link https://github.com/microsoft/TimeCraft.
MN-TSG:Continuous Time Series Generation with Irregular Observations
Jan 20, 2026Time series generation (TSG) plays a critical role in a wide range of domains, such as healthcare. However, most existing methods assume regularly sampled observations and fixed output resolutions, which are often misaligned with real-world scenarios where data are irregularly sampled and sparsely observed. This mismatch is particularly problematic in applications such as clinical monitoring, where irregular measurements must support downstream tasks requiring continuous and high-resolution time series. Neural Controlled Differential Equations (NCDEs) have shown strong potential for modeling irregular time series, yet they still face challenges in capturing complex dynamic temporal patterns and supporting continuous TSG. To address these limitations, we propose MN-TSG, a novel framework that explores Mixture-of-Experts (MoE)-based NCDEs and integrates them with existing TSG models for irregular and continuous generation tasks. The core of MN-TSG lies in a MoE-NCDE architecture with dynamically parameterized expert functions and a decoupled design that facilitates more effective optimization of MoE dynamics. Furthermore, we leverage existing TSG models to learn the joint distribution over the mixture of experts and the generated time series. This enables the framework not only to generate new samples, but also to produce appropriate expert configurations tailored to each sample, thereby supporting refined continuous TSG. Extensive experiments on ten public and synthetic datasets demonstrate the effectiveness of MN-TSG, consistently outperforming strong TSG baselines on both irregular-to-regular and irregular-to-continuous generation tasks.
Exploring Training Data Attribution under Limited Access Constraints
Sep 16, 2025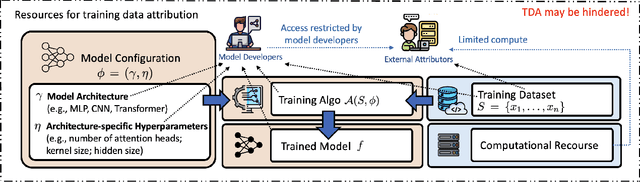
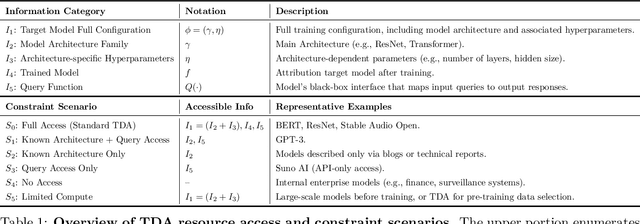
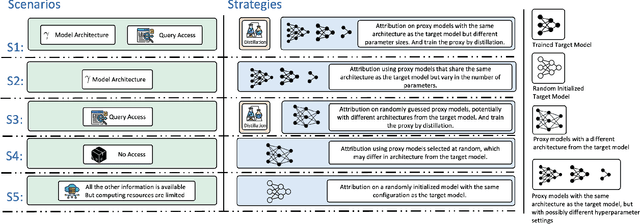

Training data attribution (TDA) plays a critical role in understanding the influence of individual training data points on model predictions. Gradient-based TDA methods, popularized by \textit{influence function} for their superior performance, have been widely applied in data selection, data cleaning, data economics, and fact tracing. However, in real-world scenarios where commercial models are not publicly accessible and computational resources are limited, existing TDA methods are often constrained by their reliance on full model access and high computational costs. This poses significant challenges to the broader adoption of TDA in practical applications. In this work, we present a systematic study of TDA methods under various access and resource constraints. We investigate the feasibility of performing TDA under varying levels of access constraints by leveraging appropriately designed solutions such as proxy models. Besides, we demonstrate that attribution scores obtained from models without prior training on the target dataset remain informative across a range of tasks, which is useful for scenarios where computational resources are limited. Our findings provide practical guidance for deploying TDA in real-world environments, aiming to improve feasibility and efficiency under limited access.
Taming Hyperparameter Sensitivity in Data Attribution: Practical Selection Without Costly Retraining
May 30, 2025Data attribution methods, which quantify the influence of individual training data points on a machine learning model, have gained increasing popularity in data-centric applications in modern AI. Despite a recent surge of new methods developed in this space, the impact of hyperparameter tuning in these methods remains under-explored. In this work, we present the first large-scale empirical study to understand the hyperparameter sensitivity of common data attribution methods. Our results show that most methods are indeed sensitive to certain key hyperparameters. However, unlike typical machine learning algorithms -- whose hyperparameters can be tuned using computationally-cheap validation metrics -- evaluating data attribution performance often requires retraining models on subsets of training data, making such metrics prohibitively costly for hyperparameter tuning. This poses a critical open challenge for the practical application of data attribution methods. To address this challenge, we advocate for better theoretical understandings of hyperparameter behavior to inform efficient tuning strategies. As a case study, we provide a theoretical analysis of the regularization term that is critical in many variants of influence function methods. Building on this analysis, we propose a lightweight procedure for selecting the regularization value without model retraining, and validate its effectiveness across a range of standard data attribution benchmarks. Overall, our study identifies a fundamental yet overlooked challenge in the practical application of data attribution, and highlights the importance of careful discussion on hyperparameter selection in future method development.
A Versatile Influence Function for Data Attribution with Non-Decomposable Loss
Dec 02, 2024



Influence function, a technique rooted in robust statistics, has been adapted in modern machine learning for a novel application: data attribution -- quantifying how individual training data points affect a model's predictions. However, the common derivation of influence functions in the data attribution literature is limited to loss functions that can be decomposed into a sum of individual data point losses, with the most prominent examples known as M-estimators. This restricts the application of influence functions to more complex learning objectives, which we refer to as non-decomposable losses, such as contrastive or ranking losses, where a unit loss term depends on multiple data points and cannot be decomposed further. In this work, we bridge this gap by revisiting the general formulation of influence function from robust statistics, which extends beyond M-estimators. Based on this formulation, we propose a novel method, the Versatile Influence Function (VIF), that can be straightforwardly applied to machine learning models trained with any non-decomposable loss. In comparison to the classical approach in statistics, the proposed VIF is designed to fully leverage the power of auto-differentiation, hereby eliminating the need for case-specific derivations of each loss function. We demonstrate the effectiveness of VIF across three examples: Cox regression for survival analysis, node embedding for network analysis, and listwise learning-to-rank for information retrieval. In all cases, the influence estimated by VIF closely resembles the results obtained by brute-force leave-one-out retraining, while being up to $10^3$ times faster to compute. We believe VIF represents a significant advancement in data attribution, enabling efficient influence-function-based attribution across a wide range of machine learning paradigms, with broad potential for practical use cases.
$\texttt{dattri}$: A Library for Efficient Data Attribution
Oct 06, 2024



Data attribution methods aim to quantify the influence of individual training samples on the prediction of artificial intelligence (AI) models. As training data plays an increasingly crucial role in the modern development of large-scale AI models, data attribution has found broad applications in improving AI performance and safety. However, despite a surge of new data attribution methods being developed recently, there lacks a comprehensive library that facilitates the development, benchmarking, and deployment of different data attribution methods. In this work, we introduce $\texttt{dattri}$, an open-source data attribution library that addresses the above needs. Specifically, $\texttt{dattri}$ highlights three novel design features. Firstly, $\texttt{dattri}$ proposes a unified and easy-to-use API, allowing users to integrate different data attribution methods into their PyTorch-based machine learning pipeline with a few lines of code changed. Secondly, $\texttt{dattri}$ modularizes low-level utility functions that are commonly used in data attribution methods, such as Hessian-vector product, inverse-Hessian-vector product or random projection, making it easier for researchers to develop new data attribution methods. Thirdly, $\texttt{dattri}$ provides a comprehensive benchmark framework with pre-trained models and ground truth annotations for a variety of benchmark settings, including generative AI settings. We have implemented a variety of state-of-the-art efficient data attribution methods that can be applied to large-scale neural network models, and will continuously update the library in the future. Using the developed $\texttt{dattri}$ library, we are able to perform a comprehensive and fair benchmark analysis across a wide range of data attribution methods. The source code of $\texttt{dattri}$ is available at https://github.com/TRAIS-Lab/dattri.
Adversarial Attacks on Data Attribution
Sep 09, 2024



Data attribution aims to quantify the contribution of individual training data points to the outputs of an AI model, which has been used to measure the value of training data and compensate data providers. Given the impact on financial decisions and compensation mechanisms, a critical question arises concerning the adversarial robustness of data attribution methods. However, there has been little to no systematic research addressing this issue. In this work, we aim to bridge this gap by detailing a threat model with clear assumptions about the adversary's goal and capabilities, and by proposing principled adversarial attack methods on data attribution. We present two such methods, Shadow Attack and Outlier Attack, both of which generate manipulated datasets to adversarially inflate the compensation. The Shadow Attack leverages knowledge about the data distribution in the AI applications, and derives adversarial perturbations through "shadow training", a technique commonly used in membership inference attacks. In contrast, the Outlier Attack does not assume any knowledge about the data distribution and relies solely on black-box queries to the target model's predictions. It exploits an inductive bias present in many data attribution methods - outlier data points are more likely to be influential - and employs adversarial examples to generate manipulated datasets. Empirically, in image classification and text generation tasks, the Shadow Attack can inflate the data-attribution-based compensation by at least 200%, while the Outlier Attack achieves compensation inflation ranging from 185% to as much as 643%.
Efficient Ensembles Improve Training Data Attribution
May 27, 2024



Training data attribution (TDA) methods aim to quantify the influence of individual training data points on the model predictions, with broad applications in data-centric AI, such as mislabel detection, data selection, and copyright compensation. However, existing methods in this field, which can be categorized as retraining-based and gradient-based, have struggled with the trade-off between computational efficiency and attribution efficacy. Retraining-based methods can accurately attribute complex non-convex models but are computationally prohibitive, while gradient-based methods are efficient but often fail for non-convex models. Recent research has shown that augmenting gradient-based methods with ensembles of multiple independently trained models can achieve significantly better attribution efficacy. However, this approach remains impractical for very large-scale applications. In this work, we discover that expensive, fully independent training is unnecessary for ensembling the gradient-based methods, and we propose two efficient ensemble strategies, DROPOUT ENSEMBLE and LORA ENSEMBLE, alternative to naive independent ensemble. These strategies significantly reduce training time (up to 80%), serving time (up to 60%), and space cost (up to 80%) while maintaining similar attribution efficacy to the naive independent ensemble. Our extensive experimental results demonstrate that the proposed strategies are effective across multiple TDA methods on diverse datasets and models, including generative settings, significantly advancing the Pareto frontier of TDA methods with better computational efficiency and attribution efficacy.
Computational Copyright: Towards A Royalty Model for AI Music Generation Platforms
Dec 11, 2023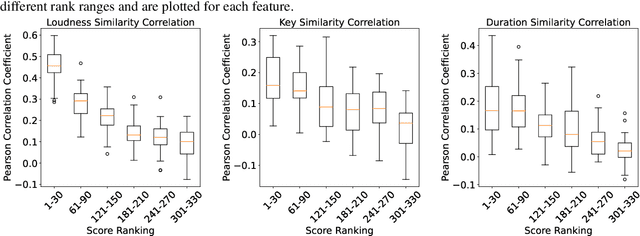
The advancement of generative AI has given rise to pressing copyright challenges, particularly in music industry. This paper focuses on the economic aspects of these challenges, emphasizing that the economic impact constitutes a central issue in the copyright arena. The complexity of the black-box generative AI technologies not only suggests but necessitates algorithmic solutions. However, such solutions have been largely missing, leading to regulatory challenges in this landscape. We aim to bridge the gap in current approaches by proposing potential royalty models for revenue sharing on AI music generation platforms. Our methodology involves a detailed analysis of existing royalty models in platforms like Spotify and YouTube, and adapting these to the unique context of AI-generated music. A significant challenge we address is the attribution of AI-generated music to influential copyrighted content in the training data. To this end, we present algorithmic solutions employing data attribution techniques. Our experimental results verify the effectiveness of these solutions. This research represents a pioneering effort in integrating technical advancements with economic and legal considerations in the field of generative AI, offering a computational copyright solution for the challenges posed by the opaque nature of AI technologies.