 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel Normalization in Convolutional Neural Network avoids Vanishing Gradients
Paper and Code


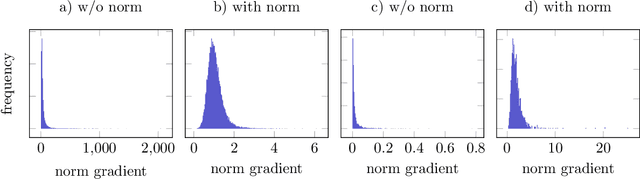
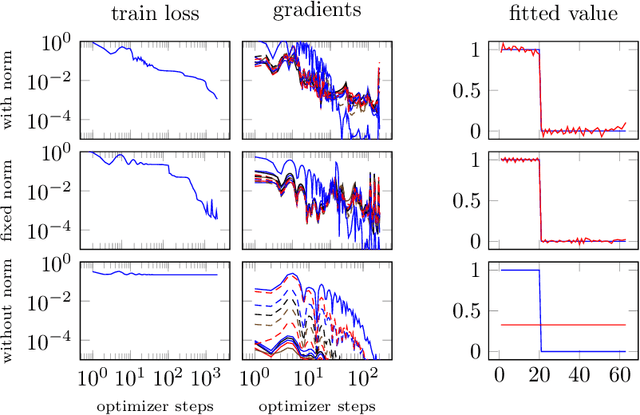
Normalization layers are widely used in deep neural networks to stabilize training. In this paper, we consider the training of convolutional neural networks with gradient descent on a single training example. This optimization problem arises in recent approaches for solving inverse problems such as the deep image prior or the deep decoder. We show that for this setup, channel normalization, which centers and normalizes each channel individually, avoids vanishing gradients, whereas, without normalization, gradients vanish which prevents efficient optimization. This effect prevails in deep single-channel linear convolutional networks, and we show that without channel normalization, gradient descent takes at least exponentially many steps to come close to an optimum. Contrary, with channel normalization, the gradients remain bounded, thus avoiding exploding gradients.