 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeqZero: Few-shot Compositional Semantic Parsing with Sequential Prompts and Zero-shot Models
Paper and Code

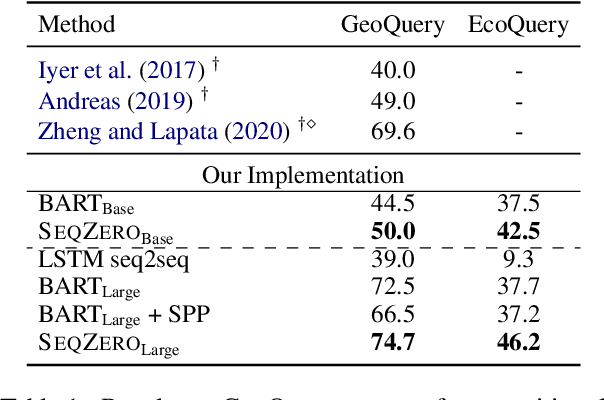

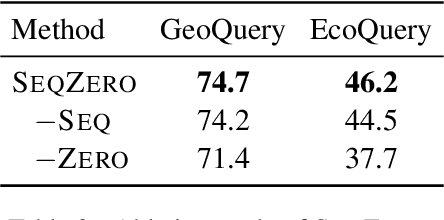
Recent research showed promising results on combining pretrained language models (LMs) with canonical utterance for few-shot semantic parsing. The canonical utterance is often lengthy and complex due to the compositional structure of formal languages. Learning to generate such canonical utterance requires significant amount of data to reach high performance. Fine-tuning with only few-shot samples, the LMs can easily forget pretrained knowledge, overfit spurious biases, and suffer from compositionally out-of-distribution generalization errors. To tackle these issues, we propose a novel few-shot semantic parsing method -- SeqZero. SeqZero decomposes the problem into a sequence of sub-problems, which correspond to the sub-clauses of the formal language. Based on the decomposition, the LMs only need to generate short answers using prompts for predicting sub-clauses. Thus, SeqZero avoids generating a long canonical utterance at once. Moreover, SeqZero employs not only a few-shot model but also a zero-shot model to alleviate the overfitting. In particular, SeqZero brings out the merits from both models via ensemble equipped with our proposed constrained rescaling. SeqZero achieves SOTA performance of BART-based models on GeoQuery and EcommerceQuery, which are two few-shot datasets with compositional data split.