 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Free Lunch But A Cheaper Supper: A General Framework for Streaming Anomaly Detection
Paper and Code
Sep 23, 2019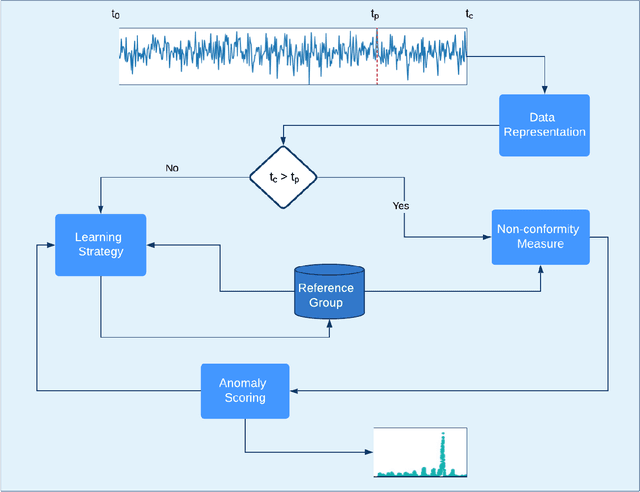
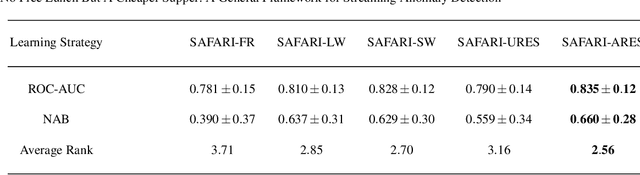
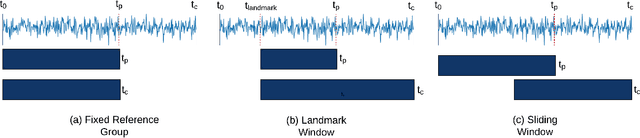
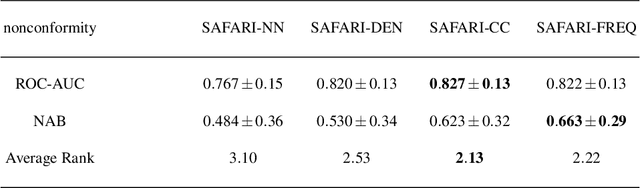
In recent years, there has been increased research interest in detecting anomalies in temporal streaming data. A variety of algorithms have been developed in the data mining community, which can be divided into two categories (i.e., general and ad hoc). In most cases, general approaches assume the one-size-fits-all solution model where a single anomaly detector can detect all anomalies in any domain. To date, there exists no single general method that has been shown to outperform the others across different anomaly types, use cases and datasets. On the other hand, ad hoc approaches that are designed for a specific application lack flexibility. Adapting an existing algorithm is not straightforward if the specific constraints or requirements for the existing task change. In this paper, we propose SAFARI, a general framework formulated by abstracting and unifying the fundamental tasks in streaming anomaly detection, which provides a flexible and extensible anomaly detection procedure. SAFARI helps to facilitate more elaborate algorithm comparisons by allowing us to isolate the effects of shared and unique characteristics of different algorithms on detection performance. Using SAFARI, we have implemented various anomaly detectors and identified a research gap that motivates us to propose a novel learning strategy in this work. We conducted an extensive evaluation study of 20 detectors that are composed using SAFARI and compared their performances using real-world benchmark datasets with different properties. The results indicate that there is no single superior detector that works well for every case, proving our hypothesis that "there is no free lunch" in the streaming anomaly detection world. Finally, we discuss the benefits and drawbacks of each method in-depth and draw a set of conclusions to guide future users of SAFARI.