 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Measuring and Quantifying Performance: Error Rates, Surrogate Loss, and an Example in SSL
Jul 13, 2017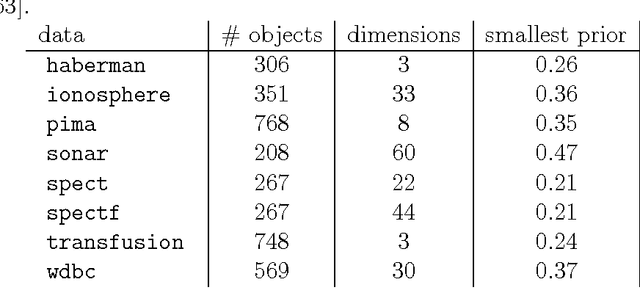
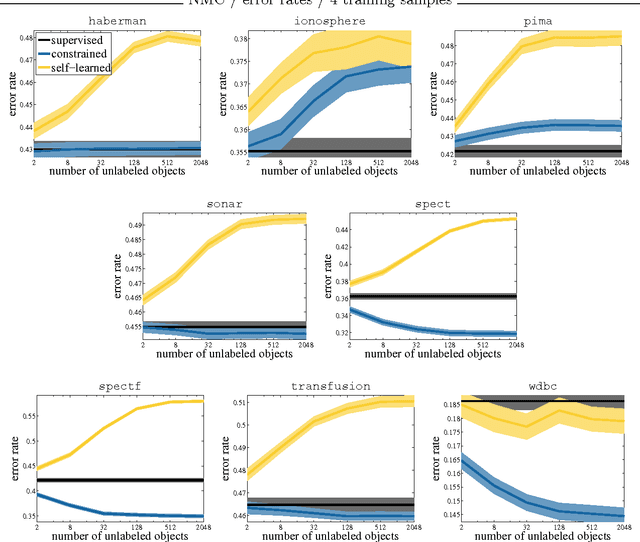


In various approaches to learning, notably in domain adaptation, active learning, learning under covariate shift, semi-supervised learning, learning with concept drift, and the like, one often wants to compare a baseline classifier to one or more advanced (or at least different) strategies. In this chapter, we basically argue that if such classifiers, in their respective training phases, optimize a so-called surrogate loss that it may also be valuable to compare the behavior of this loss on the test set, next to the regular classification error rate. It can provide us with an additional view on the classifiers' relative performances that error rates cannot capture. As an example, limited but convincing empirical results demonstrates that we may be able to find semi-supervised learning strategies that can guarantee performance improvements with increasing numbers of unlabeled data in terms of log-likelihood. In contrast, the latter may be impossible to guarantee for the classification error rate.