 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWT-UMI: Tactile-based Whole-Body Manipulation via Force-Supervised Contact-Aware Planning
Jun 11, 2026Whole-body humanoid manipulation of bulky, deformable, and shared-load objects requires distributed contact sensing and explicit force regulation, yet most imitation policies treat contact force only implicitly. On the other hand, different demonstration sources provide complementary modalities with inherent trade-offs: human demonstrations capture natural contact forces but not robot-executable actions, while teleoperation directly records robot actions but with less natural force regulation. This paper presents \textbf{WT-UMI}, a wearable whole-body tactile interface worn by human operators or mounted on humanoids, providing accurate observations of tactile images, contact forces, and end-effector poses across both human demonstration and humanoid teleoperation modes. We introduce a force-conditioned target-pose correction module that converts measured human poses into contact-aware robot targets by learning corrections from teleoperation data. To leverage the natural force interaction in human data, we propose a force-supervised planner that predicts end-effector pose chunks and contact-force trajectories. The predicted contact force serves as the reference for a tactile-based admittance controller. Across five contact-rich tasks spanning deformable objects, bulky rigid objects, and human--humanoid collaboration, WT-UMI improves success rate and reduces contact-position tracking error over four policy baselines. Our project page is available at https://wt-umi.github.io/WTUMI/.
Per-Instance Algorithm Selection for Recommender Systems via Instance Clustering
Dec 30, 2020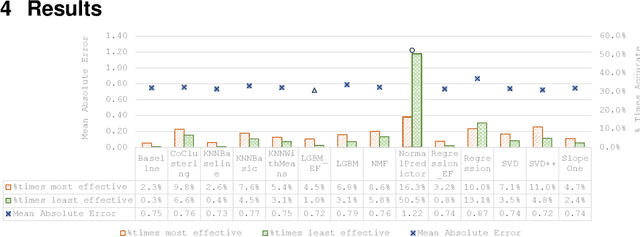

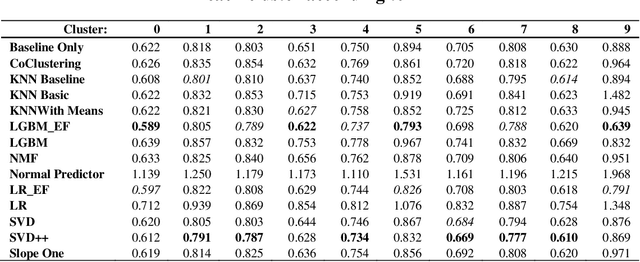

Recommendation algorithms perform differently if the users, recommendation contexts, applications, and user interfaces vary even slightly. It is similarly observed in other fields, such as combinatorial problem solving, that algorithms perform differently for each instance presented. In those fields, meta-learning is successfully used to predict an optimal algorithm for each instance, to improve overall system performance. Per-instance algorithm selection has thus far been unsuccessful for recommender systems. In this paper we propose a per-instance meta-learner that clusters data instances and predicts the best algorithm for unseen instances according to cluster membership. We test our approach using 10 collaborative- and 4 content-based filtering algorithms, for varying clustering parameters, and find a significant improvement over the best performing base algorithm at alpha=0.053 (MAE: 0.7107 vs LightGBM 0.7214; t-test). We also explore the performances of our base algorithms on a ratings dataset and empirically show that the error of a perfect algorithm selector monotonically decreases for larger pools of algorithm. To the best of our knowledge, this is the first effective meta-learning technique for per-instance algorithm selection in recommender systems.
Siamese Meta-Learning and Algorithm Selection with 'Algorithm-Performance Personas' [Proposal]
Jun 23, 2020![Figure 1 for Siamese Meta-Learning and Algorithm Selection with 'Algorithm-Performance Personas' [Proposal]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fdded217ac3c93998376d8e0ffea5cbe23772a43e%2F2-Figure1-1.png&w=640&q=75)
![Figure 2 for Siamese Meta-Learning and Algorithm Selection with 'Algorithm-Performance Personas' [Proposal]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fdded217ac3c93998376d8e0ffea5cbe23772a43e%2F2-Figure2-1.png&w=640&q=75)
![Figure 3 for Siamese Meta-Learning and Algorithm Selection with 'Algorithm-Performance Personas' [Proposal]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fdded217ac3c93998376d8e0ffea5cbe23772a43e%2F3-Figure3-1.png&w=640&q=75)
![Figure 4 for Siamese Meta-Learning and Algorithm Selection with 'Algorithm-Performance Personas' [Proposal]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fdded217ac3c93998376d8e0ffea5cbe23772a43e%2F4-Figure4-1.png&w=640&q=75)
Automated per-instance algorithm selection often outperforms single learners. Key to algorithm selection via meta-learning is often the (meta) features, which sometimes though do not provide enough information to train a meta-learner effectively. We propose a Siamese Neural Network architecture for automated algorithm selection that focuses more on 'alike performing' instances than meta-features. Our work includes a novel performance metric and method for selecting training samples. We introduce further the concept of 'Algorithm Performance Personas' that describe instances for which the single algorithms perform alike. The concept of 'alike performing algorithms' as ground truth for selecting training samples is novel and provides a huge potential as we believe. In this proposal, we outline our ideas in detail and provide the first evidence that our proposed metric is better suitable for training sample selection that standard performance metrics such as absolute errors.
NaïveRole: Author-Contribution Extraction and Parsing from Biomedical Manuscripts
Dec 15, 2019
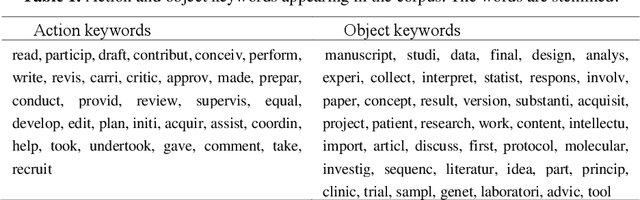
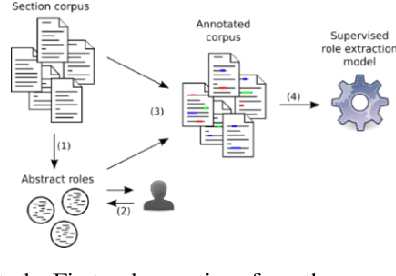
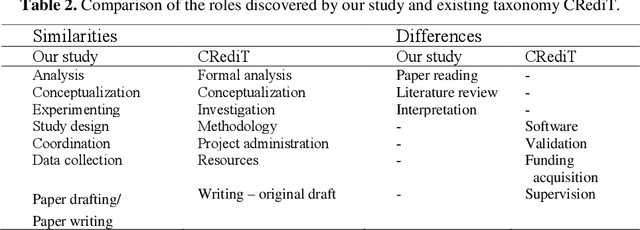
Information about the contributions of individual authors to scientific publications is important for assessing authors' achievements. Some biomedical publications have a short section that describes authors' roles and contributions. It is usually written in natural language and hence author contributions cannot be trivially extracted in a machine-readable format. In this paper, we present 1) A statistical analysis of roles in author contributions sections, and 2) Na\"iveRole, a novel approach to extract structured authors' roles from author contribution sections. For the first part, we used co-clustering techniques, as well as Open Information Extraction, to semi-automatically discover the popular roles within a corpus of 2,000 contributions sections from PubMed Central. The discovered roles were used to automatically build a training set for Na\"iveRole, our role extractor approach, based on Na\"ive Bayes. Na\"iveRole extracts roles with a micro-averaged precision of 0.68, recall of 0.48 and F1 of 0.57. It is, to the best of our knowledge, the first attempt to automatically extract author roles from research papers. This paper is an extended version of a previous poster published at JCDL 2018.
* arXiv admin note: substantial text overlap with arXiv:1802.01174
The Architecture of Mr. DLib's Scientific Recommender-System API
Nov 26, 2018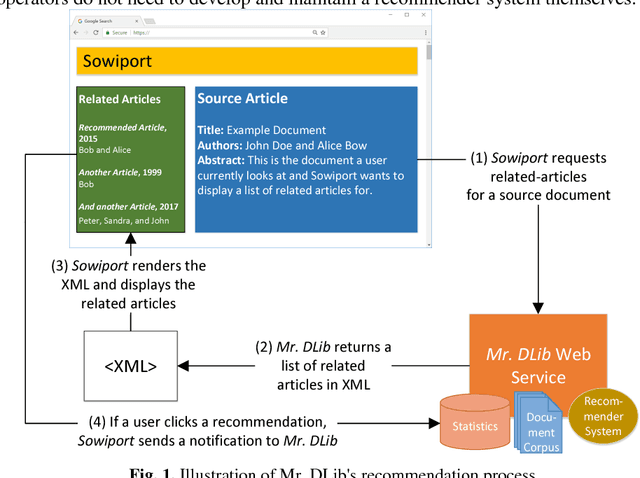
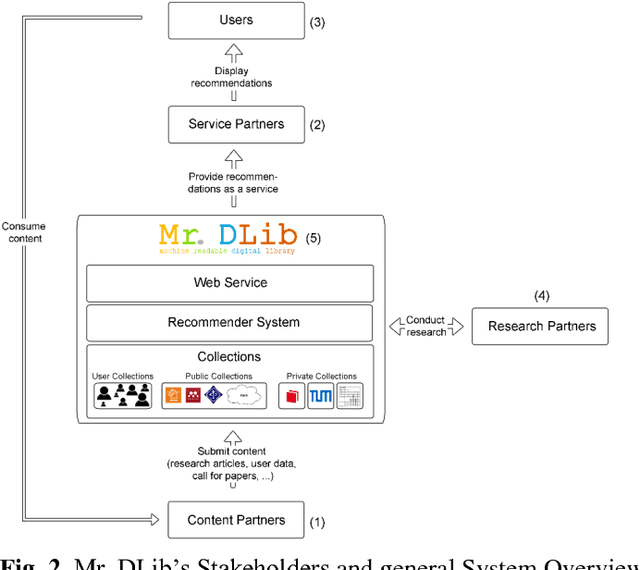
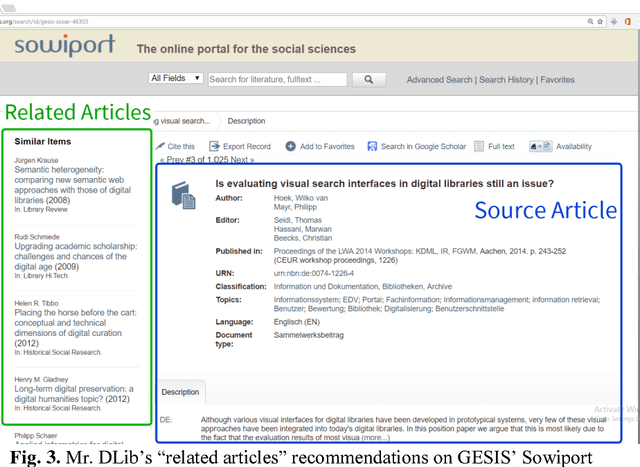
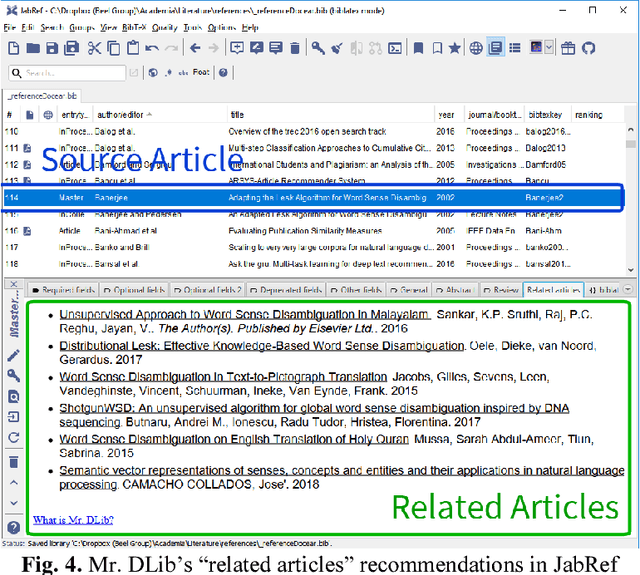
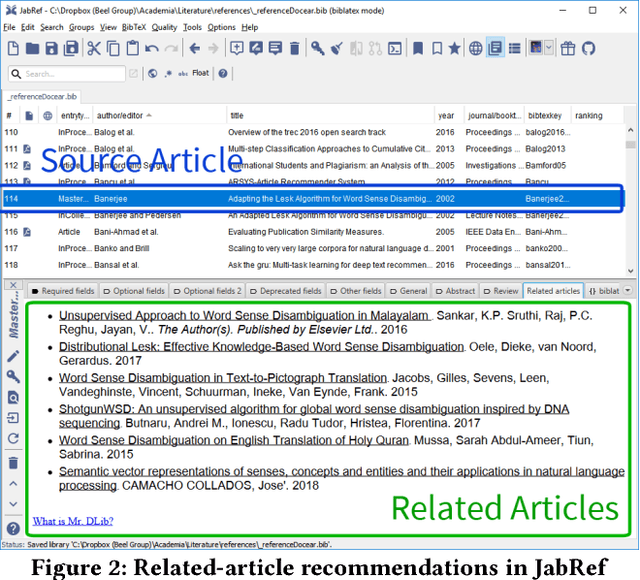
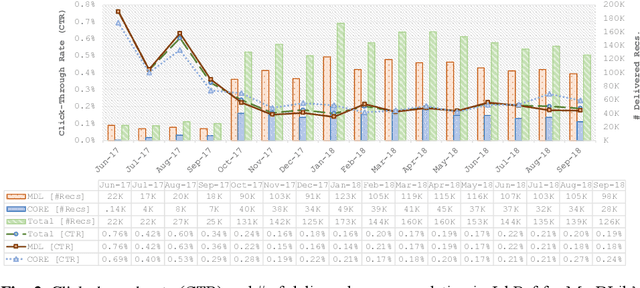
Recommender systems in academia are not widely available. This may be in part due to the difficulty and cost of developing and maintaining recommender systems. Many operators of academic products such as digital libraries and reference managers avoid this effort, although a recommender system could provide significant benefits to their users. In this paper, we introduce Mr. DLib's "Recommendations as-a-Service" (RaaS) API that allows operators of academic products to easily integrate a scientific recommender system into their products. Mr. DLib generates recommendations for research articles but in the future, recommendations may include call for papers, grants, etc. Operators of academic products can request recommendations from Mr. DLib and display these recommendations to their users. Mr. DLib can be integrated in just a few hours or days; creating an equivalent recommender system from scratch would require several months for an academic operator. Mr. DLib has been used by GESIS Sowiport and by the reference manager JabRef. Mr. DLib is open source and its goal is to facilitate the application of, and research on, scientific recommender systems. In this paper, we present the motivation for Mr. DLib, the architecture and details about the effectiveness. Mr. DLib has delivered 94m recommendations over a span of two years with an average click-through rate of 0.12%.
RARD II: The 2nd Related-Article Recommendation Dataset
Jul 20, 2018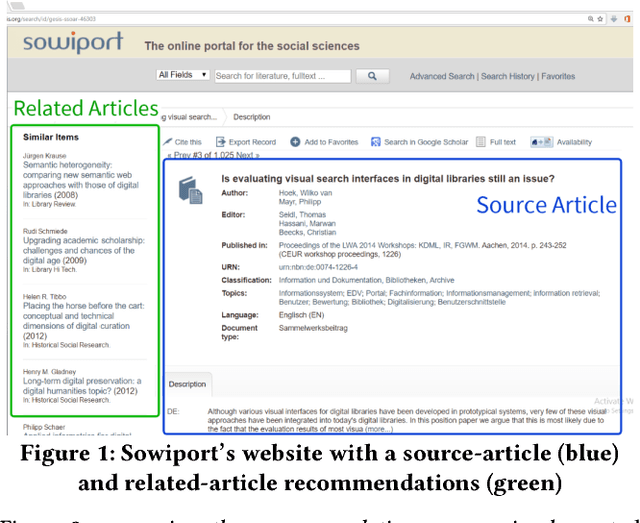
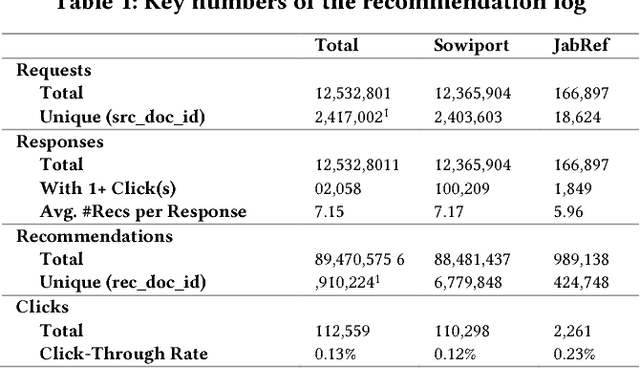
The main contribution of this paper is to introduce and describe a new recommender-systems dataset (RARD II). It is based on data from a recommender-system in the digital library and reference management software domain. As such, it complements datasets from other domains such as books, movies, and music. The RARD II dataset encompasses 89m recommendations, covering an item-space of 24m unique items. RARD II provides a range of rich recommendation data, beyond conventional ratings. For example, in addition to the usual ratings matrices, RARD II includes the original recommendation logs, which provide a unique insight into many aspects of the algorithms that generated the recommendations. In this paper, we summarise the key features of this dataset release, describing how it was generated and discussing some of its unique features.
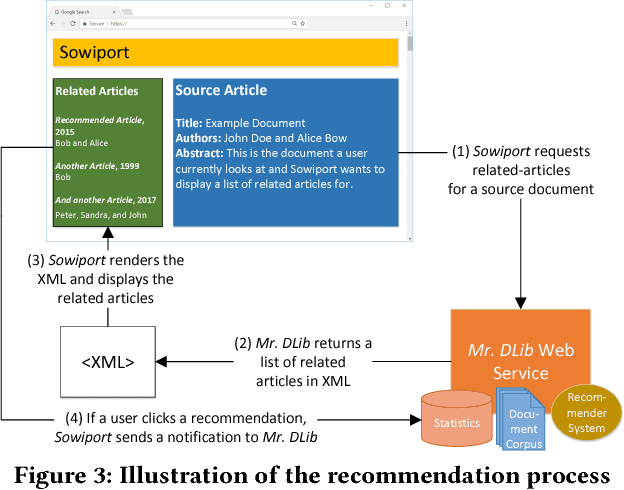
Mr. DLib's Living Lab for Scholarly Recommendations
Jul 19, 2018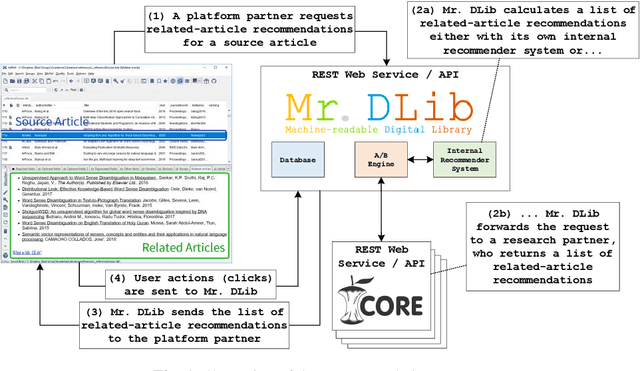
We introduce the first living lab for scholarly recommender systems. This lab allows recommender-system researchers to conduct online evaluations of their novel algorithms for scholarly recommendations, i.e., research papers, citations, conferences, research grants etc. Recommendations are delivered through the living lab's API in platforms such as reference management software and digital libraries. The living lab is built on top of the recommender system as-a-service Mr. DLib. Current partners are the reference management software JabRef and the CORE research team. We present the architecture of Mr. DLib's living lab as well as usage statistics on the first ten months of operating it. During this time, 970,517 recommendations were delivered with a mean click-through rate of 0.22%.