 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting Transformer-Transducer Based Speaker Change Detection With Token-Level Training Loss
Paper and Code
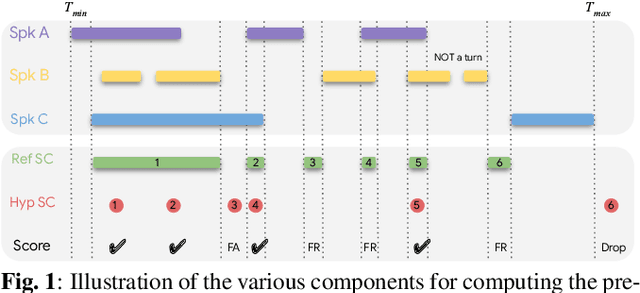
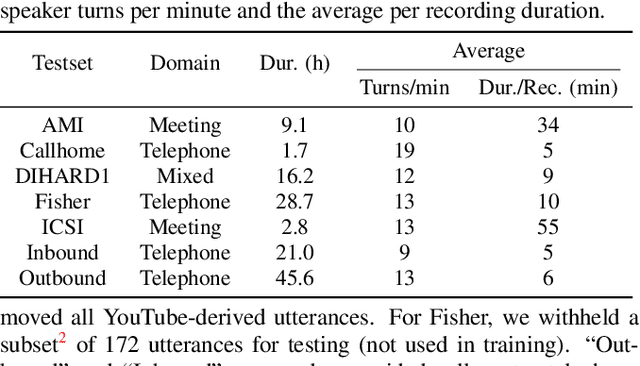
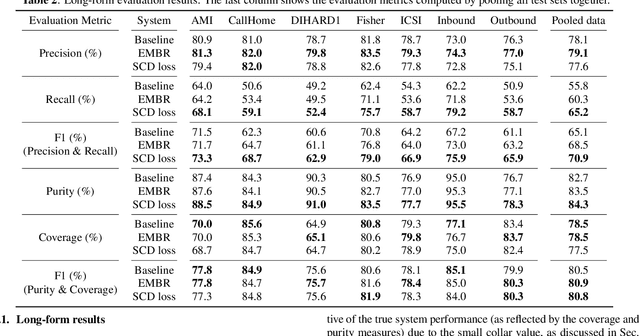
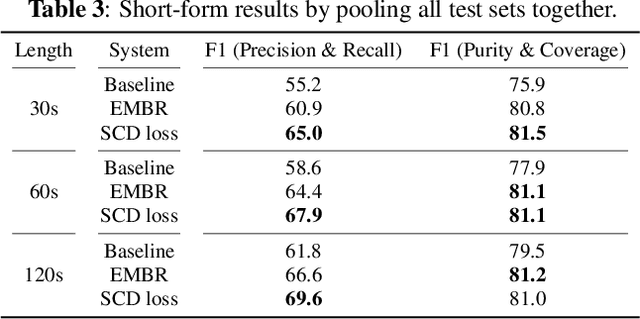
In this work we propose a novel token-based training strategy that improves Transformer-Transducer (T-T) based speaker change detection (SCD) performance. The conventional T-T based SCD model loss optimizes all output tokens equally. Due to the sparsity of the speaker changes in the training data, the conventional T-T based SCD model loss leads to sub-optimal detection accuracy. To mitigate this issue, we use a customized edit-distance algorithm to estimate the token-level SCD false accept (FA) and false reject (FR) rates during training and optimize model parameters to minimize a weighted combination of the FA and FR, focusing the model on accurately predicting speaker changes. We also propose a set of evaluation metrics that align better with commercial use cases. Experiments on a group of challenging real-world datasets show that the proposed training method can significantly improve the overall performance of the SCD model with the same number of parameters.