 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurn-to-Diarize: Online Speaker Diarization Constrained by Transformer Transducer Speaker Turn Detection
Paper and Code
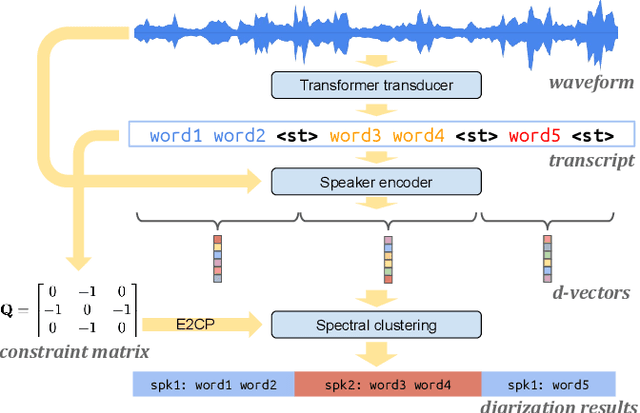

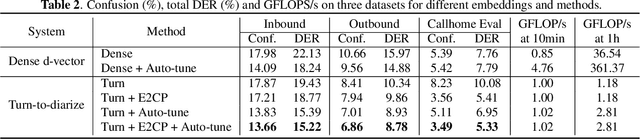
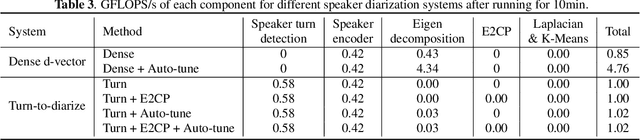
In this paper, we present a novel speaker diarization system for streaming on-device applications. In this system, we use a transformer transducer to detect the speaker turns, represent each speaker turn by a speaker embedding, then cluster these embeddings with constraints from the detected speaker turns. Compared with conventional clustering-based diarization systems, our system largely reduces the computational cost of clustering due to the sparsity of speaker turns. Unlike other supervised speaker diarization systems which require annotations of time-stamped speaker labels for training, our system only requires including speaker turn tokens during the transcribing process, which largely reduces the human efforts involved in data collection.