 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoisy student-teacher training for robust keyword spotting
Jun 03, 2021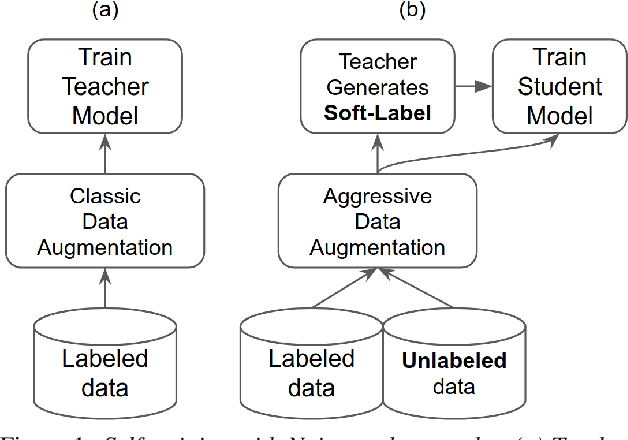

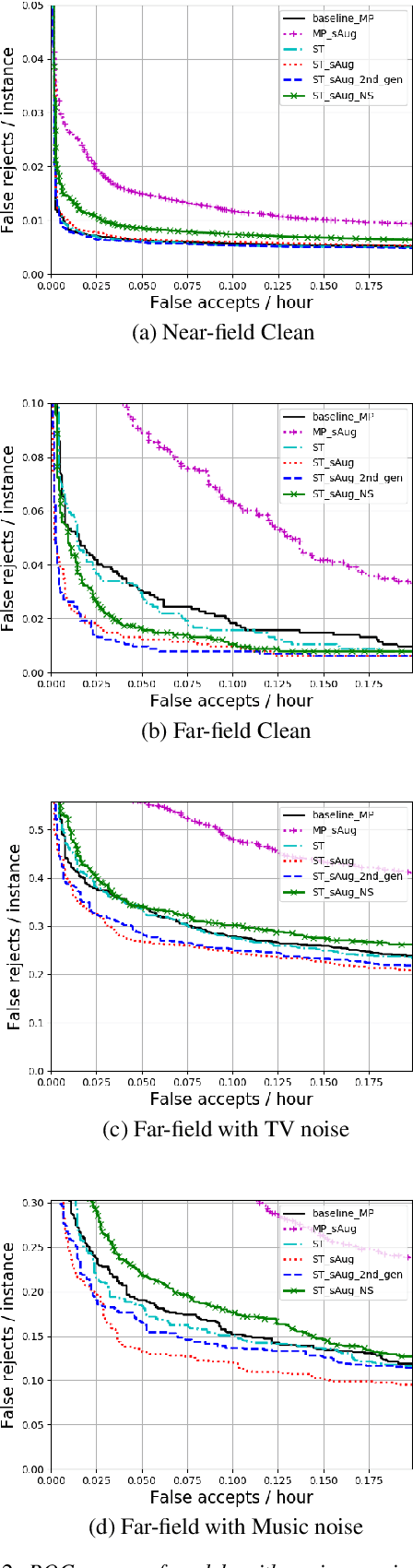
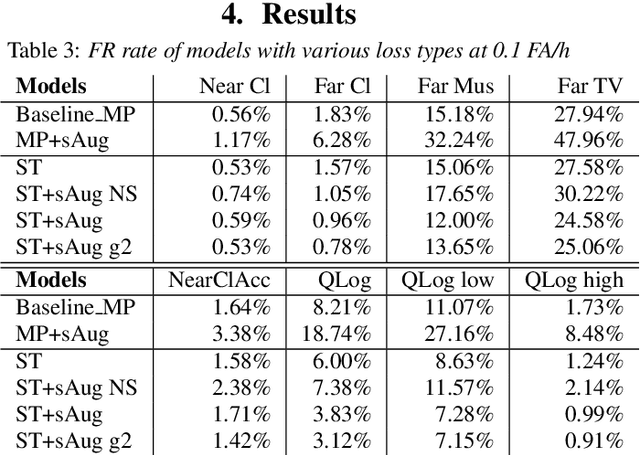
We propose self-training with noisy student-teacher approach for streaming keyword spotting, that can utilize large-scale unlabeled data and aggressive data augmentation. The proposed method applies aggressive data augmentation (spectral augmentation) on the input of both student and teacher and utilize unlabeled data at scale, which significantly boosts the accuracy of student against challenging conditions. Such aggressive augmentation usually degrades model performance when used with supervised training with hard-labeled data. Experiments show that aggressive spec augmentation on baseline supervised training method degrades accuracy, while the proposed self-training with noisy student-teacher training improves accuracy of some difficult-conditioned test sets by as much as 60%.
Training Keyword Spotting Models on Non-IID Data with Federated Learning
Jun 04, 2020
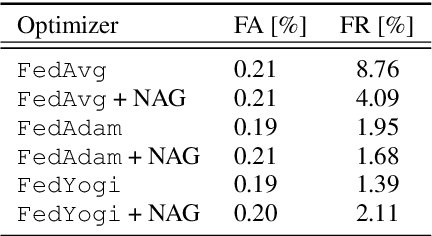

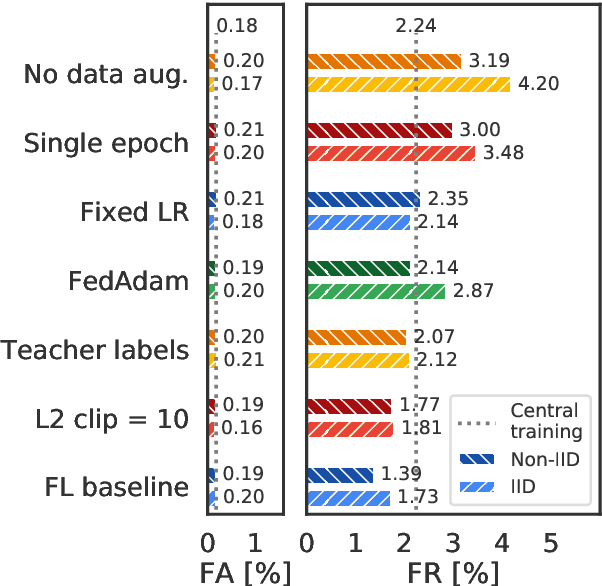
We demonstrate that a production-quality keyword-spotting model can be trained on-device using federated learning and achieve comparable false accept and false reject rates to a centrally-trained model. To overcome the algorithmic constraints associated with fitting on-device data (which are inherently non-independent and identically distributed), we conduct thorough empirical studies of optimization algorithms and hyperparameter configurations using large-scale federated simulations. To overcome resource constraints, we replace memory intensive MTR data augmentation with SpecAugment, which reduces the false reject rate by 56%. Finally, to label examples (given the zero visibility into on-device data), we explore teacher-student training.
Learning To Detect Keyword Parts And Whole By Smoothed Max Pooling
Jan 25, 2020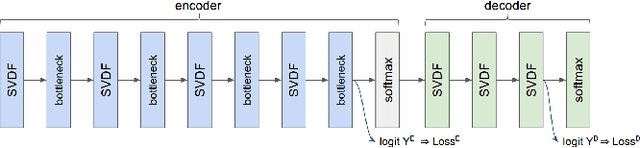

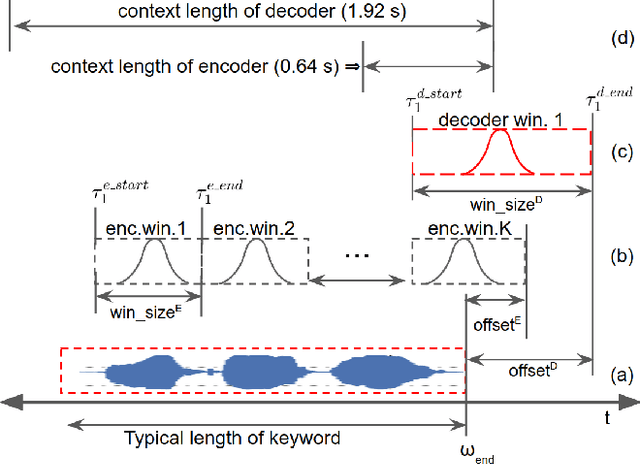
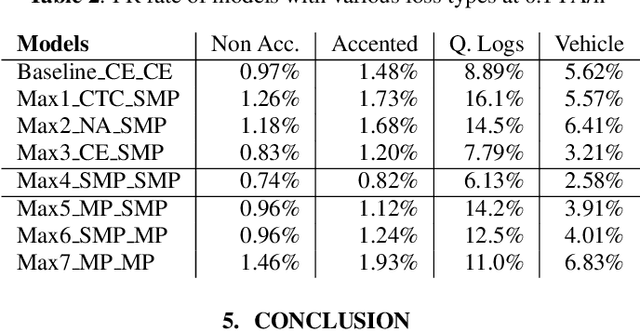
We propose smoothed max pooling loss and its application to keyword spotting systems. The proposed approach jointly trains an encoder (to detect keyword parts) and a decoder (to detect whole keyword) in a semi-supervised manner. The proposed new loss function allows training a model to detect parts and whole of a keyword, without strictly depending on frame-level labeling from LVCSR (Large vocabulary continuous speech recognition), making further optimization possible. The proposed system outperforms the baseline keyword spotting model in [1] due to increased optimizability. Further, it can be more easily adapted for on-device learning applications due to reduced dependency on LVCSR.