Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Keyword Spotting Models on Non-IID Data with Federated Learning
Paper and Code
Jun 04, 2020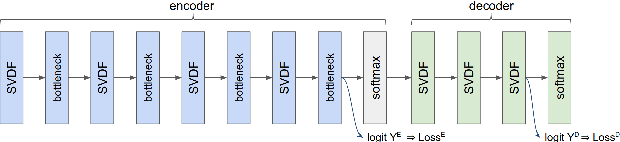
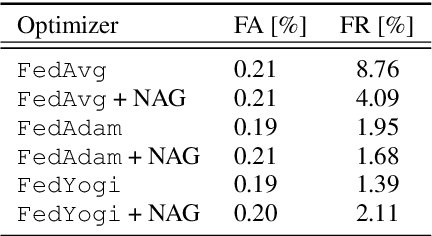

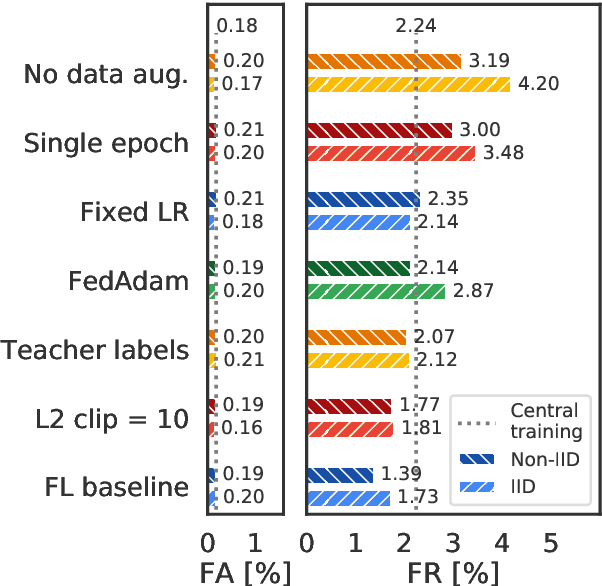
We demonstrate that a production-quality keyword-spotting model can be trained on-device using federated learning and achieve comparable false accept and false reject rates to a centrally-trained model. To overcome the algorithmic constraints associated with fitting on-device data (which are inherently non-independent and identically distributed), we conduct thorough empirical studies of optimization algorithms and hyperparameter configurations using large-scale federated simulations. To overcome resource constraints, we replace memory intensive MTR data augmentation with SpecAugment, which reduces the false reject rate by 56%. Finally, to label examples (given the zero visibility into on-device data), we explore teacher-student training.
* Submitted to Interspeech 2020
View paper on