Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning To Detect Keyword Parts And Whole By Smoothed Max Pooling
Jan 25, 2020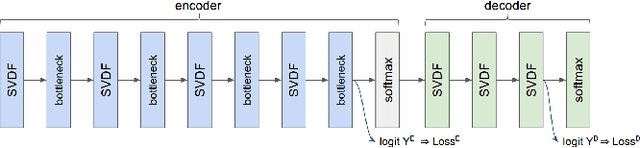

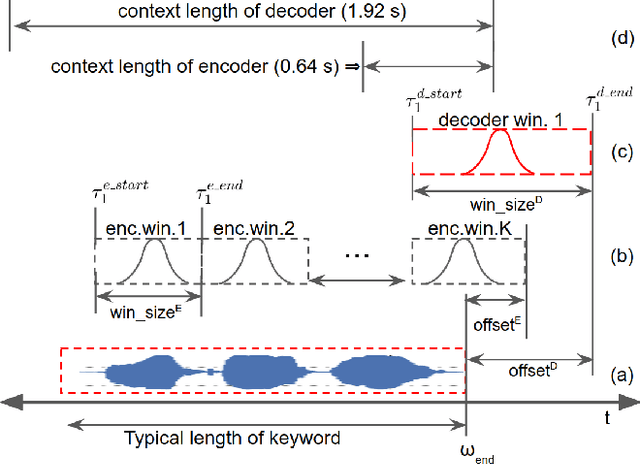
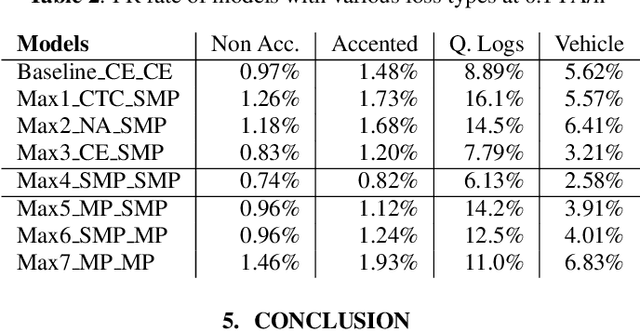
We propose smoothed max pooling loss and its application to keyword spotting systems. The proposed approach jointly trains an encoder (to detect keyword parts) and a decoder (to detect whole keyword) in a semi-supervised manner. The proposed new loss function allows training a model to detect parts and whole of a keyword, without strictly depending on frame-level labeling from LVCSR (Large vocabulary continuous speech recognition), making further optimization possible. The proposed system outperforms the baseline keyword spotting model in [1] due to increased optimizability. Further, it can be more easily adapted for on-device learning applications due to reduced dependency on LVCSR.
* Accepted in International Conference on Acoustics, Speech, and Signal
Processing 2020
Via