 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed Federated Learning: Joint Decentralized and Centralized Learning
Paper and Code
May 26, 2022
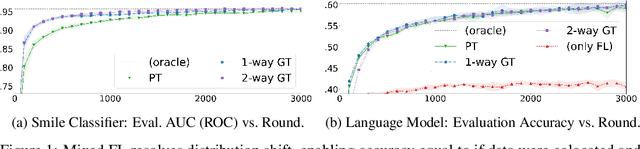
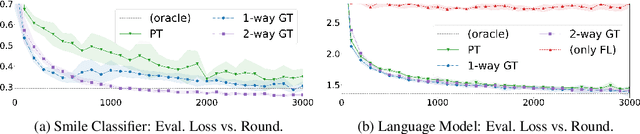
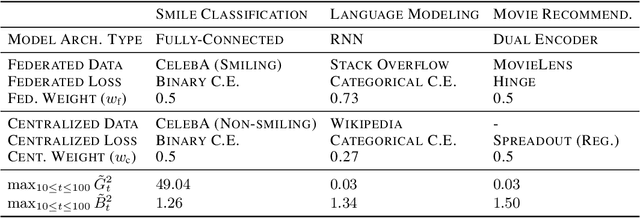
Federated learning (FL) enables learning from decentralized privacy-sensitive data, with computations on raw data confined to take place at edge clients. This paper introduces mixed FL, which incorporates an additional loss term calculated at the coordinating server (while maintaining FL's private data restrictions). There are numerous benefits. For example, additional datacenter data can be leveraged to jointly learn from centralized (datacenter) and decentralized (federated) training data and better match an expected inference data distribution. Mixed FL also enables offloading some intensive computations (e.g., embedding regularization) to the server, greatly reducing communication and client computation load. For these and other mixed FL use cases, we present three algorithms: PARALLEL TRAINING, 1-WAY GRADIENT TRANSFER, and 2-WAY GRADIENT TRANSFER. We state convergence bounds for each, and give intuition on which are suited to particular mixed FL problems. Finally we perform extensive experiments on three tasks, demonstrating that mixed FL can blend training data to achieve an oracle's accuracy on an inference distribution, and can reduce communication and computation overhead by over 90%. Our experiments confirm theoretical predictions of how algorithms perform under different mixed FL problem settings.