 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution-Aware Reward Estimation for Test-Time Reinforcement Learning
Jan 29, 2026Test-time reinforcement learning (TTRL) enables large language models (LLMs) to self-improve on unlabeled inputs, but its effectiveness critically depends on how reward signals are estimated without ground-truth supervision. Most existing TTRL methods rely on majority voting (MV) over rollouts to produce deterministic rewards, implicitly assuming that the majority rollout provides a reliable learning signal. We show that this assumption is fragile: MV reduces the rollout distribution into a single outcome, discarding information about non-majority but correct actions candidates, and yields systematically biased reward estimates. To address this, we propose Distribution-AwareReward Estimation (DARE), which shifts reward estimation from a single majority outcome to the full empirical rollout distribution. DARE further augments this distribution-based reward with an exploration bonus and a distribution pruning mechanism for non-majority rollout exploration and reward denoise, yielding a more informative and robust reward estimation. Extensive experiments on challenging reasoning benchmarks show that DARE improves optimization stability and final performance over recent baselines, achieving relative improvements of 25.3% on challenging AIME 2024 and 5.3% on AMC.
Neurons: Emulating the Human Visual Cortex Improves Fidelity and Interpretability in fMRI-to-Video Reconstruction
Mar 14, 2025


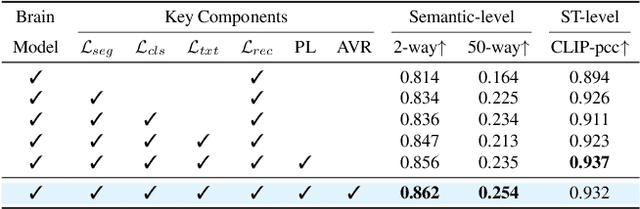
Decoding visual stimuli from neural activity is essential for understanding the human brain. While fMRI methods have successfully reconstructed static images, fMRI-to-video reconstruction faces challenges due to the need for capturing spatiotemporal dynamics like motion and scene transitions. Recent approaches have improved semantic and perceptual alignment but struggle to integrate coarse fMRI data with detailed visual features. Inspired by the hierarchical organization of the visual system, we propose NEURONS, a novel framework that decouples learning into four correlated sub-tasks: key object segmentation, concept recognition, scene description, and blurry video reconstruction. This approach simulates the visual cortex's functional specialization, allowing the model to capture diverse video content. In the inference stage, NEURONS generates robust conditioning signals for a pre-trained text-to-video diffusion model to reconstruct the videos. Extensive experiments demonstrate that NEURONS outperforms state-of-the-art baselines, achieving solid improvements in video consistency (26.6%) and semantic-level accuracy (19.1%). Notably, NEURONS shows a strong functional correlation with the visual cortex, highlighting its potential for brain-computer interfaces and clinical applications. Code and model weights will be available at: https://github.com/xmed-lab/NEURONS.