 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatient-Level Diagnosis of Acute Myeloid Leukemia via Deep Learning Analysis of Bone Marrow Smear
Jun 09, 2026Bone marrow smear review remains important for acute myeloid leukemia (AML) assessment, but manual single-cell interpretation is labor-intensive and patient-level diagnosis requires aggregation of many cellular observations. We present a cell-to-patient deep learning pipeline for AML-assisted diagnosis from bone marrow smear images. The study included 258 patients from six anonymized centers, including a main cohort of 169 patients from Centers 1-3 and an external validation cohort of 89 patients from Centers 4-6. A 16-category cell annotation vocabulary was used to describe the global cellular composition, including granulocytic, monocytic, erythroid, lymphoid, eosinophilic, and other cells. Rather than identifying strict AML blasts or leukemic blasts, the model targets an expert-defined composite category termed Composite Blast-like Cells (CBLC), comprising N, N1, M, M1, R, R1, J, and J1 according to the project-wide morphological standard. A fixed YOLO-based segmentation module detected cells, predicted contours were matched to expert polygon annotations by contour IoU, and standardized single-cell crops were generated. An EfficientNet-B0 classifier was trained through a two-stage GT-to-YOLO and YOLO-to-YOLO strategy with class-imbalance correction, center-border regularization, and morphology-assisted supervision. Cell-level predictions were aggregated into patient-level CBLC ratios for AML-oriented diagnostic support. The pipeline achieved stable internal validation and maintained external generalization, with ensemble weighted F1-scores of 0.9076, 0.8696, and 0.9124 on Centers 4, 5, and 6, respectively.
MultiEYE: Dataset and Benchmark for OCT-Enhanced Retinal Disease Recognition from Fundus Images
Dec 12, 2024



Existing multi-modal learning methods on fundus and OCT images mostly require both modalities to be available and strictly paired for training and testing, which appears less practical in clinical scenarios. To expand the scope of clinical applications, we formulate a novel setting, "OCT-enhanced disease recognition from fundus images", that allows for the use of unpaired multi-modal data during the training phase and relies on the widespread fundus photographs for testing. To benchmark this setting, we present the first large multi-modal multi-class dataset for eye disease diagnosis, MultiEYE, and propose an OCT-assisted Conceptual Distillation Approach (OCT-CoDA), which employs semantically rich concepts to extract disease-related knowledge from OCT images and leverage them into the fundus model. Specifically, we regard the image-concept relation as a link to distill useful knowledge from the OCT teacher model to the fundus student model, which considerably improves the diagnostic performance based on fundus images and formulates the cross-modal knowledge transfer into an explainable process. Through extensive experiments on the multi-disease classification task, our proposed OCT-CoDA demonstrates remarkable results and interpretability, showing great potential for clinical application. Our dataset and code are available at https://github.com/xmed-lab/MultiEYE.
Best of Many in Both Worlds: Online Resource Allocation with Predictions under Unknown Arrival Model
Feb 21, 2024
Online decision-makers today can often obtain predictions on future variables, such as arrivals, demands, inventories, and so on. These predictions can be generated from simple forecasting algorithms for univariate time-series, all the way to state-of-the-art machine learning models that leverage multiple time-series and additional feature information. However, the prediction quality is often unknown to decisions-makers a priori, hence blindly following the predictions can be harmful. In this paper, we address this problem by giving algorithms that take predictions as inputs and perform robustly against the unknown prediction quality. We consider the online resource allocation problem, one of the most generic models in revenue management and online decision-making. In this problem, a decision maker has a limited amount of resources, and requests arrive sequentially. For each request, the decision-maker needs to decide on an action, which generates a certain amount of rewards and consumes a certain amount of resources, without knowing the future requests. The decision-maker's objective is to maximize the total rewards subject to resource constraints. We take the shadow price of each resource as prediction, which can be obtained by predictions on future requests. Prediction quality is naturally defined to be the $\ell_1$ distance between the prediction and the actual shadow price. Our main contribution is an algorithm which takes the prediction of unknown quality as an input, and achieves asymptotically optimal performance under both requests arrival models (stochastic and adversarial) without knowing the prediction quality and the requests arrival model beforehand. We show our algorithm's performance matches the best achievable performance of any algorithm had the arrival models and the accuracy of the predictions been known. We empirically validate our algorithm with experiments.
Vessel-Promoted OCT to OCTA Image Translation by Heuristic Contextual Constraints
Mar 13, 2023Optical Coherence Tomography Angiography (OCTA) has become increasingly vital in the clinical screening of fundus diseases due to its ability to capture accurate 3D imaging of blood vessels in a non-contact scanning manner. However, the acquisition of OCTA images remains challenging due to the requirement of exclusive sensors and expensive devices. In this paper, we propose a novel framework, TransPro, that translates 3D Optical Coherence Tomography (OCT) images into exclusive 3D OCTA images using an image translation pattern. Our main objective is to address two issues in existing image translation baselines, namely, the aimlessness in the translation process and incompleteness of the translated object. The former refers to the overall quality of the translated OCTA images being satisfactory, but the retinal vascular quality being low. The latter refers to incomplete objects in translated OCTA images due to the lack of global contexts. TransPro merges a 2D retinal vascular segmentation model and a 2D OCTA image translation model into a 3D image translation baseline for the 2D projection map projected by the translated OCTA images. The 2D retinal vascular segmentation model can improve attention to the retinal vascular, while the 2D OCTA image translation model introduces beneficial heuristic contextual information. Extensive experimental results on two challenging datasets demonstrate that TransPro can consistently outperform existing approaches with minimal computational overhead during training and none during testing.
Neuro-Symbolic Learning: Principles and Applications in Ophthalmology
Jul 31, 2022
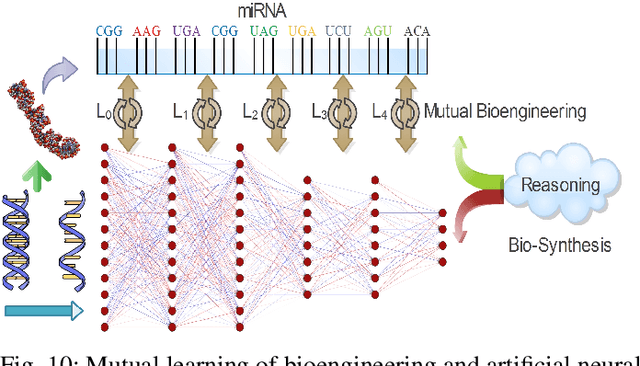
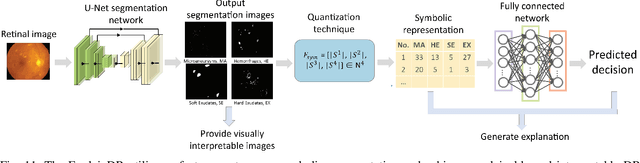
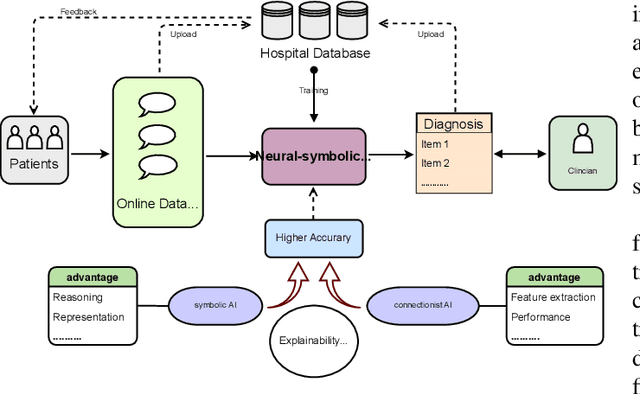
Neural networks have been rapidly expanding in recent years, with novel strategies and applications. However, challenges such as interpretability, explainability, robustness, safety, trust, and sensibility remain unsolved in neural network technologies, despite the fact that they will unavoidably be addressed for critical applications. Attempts have been made to overcome the challenges in neural network computing by representing and embedding domain knowledge in terms of symbolic representations. Thus, the neuro-symbolic learning (NeSyL) notion emerged, which incorporates aspects of symbolic representation and bringing common sense into neural networks (NeSyL). In domains where interpretability, reasoning, and explainability are crucial, such as video and image captioning, question-answering and reasoning, health informatics, and genomics, NeSyL has shown promising outcomes. This review presents a comprehensive survey on the state-of-the-art NeSyL approaches, their principles, advances in machine and deep learning algorithms, applications such as opthalmology, and most importantly, future perspectives of this emerging field.