 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoVL:Exploring Fusion Strategies for the Domain-Adaptive Application of Pretrained Models in Medical Imaging Tasks
Paper and Code
May 13, 2024
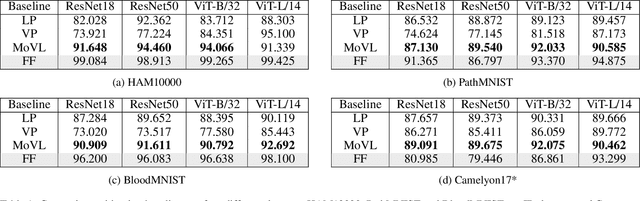
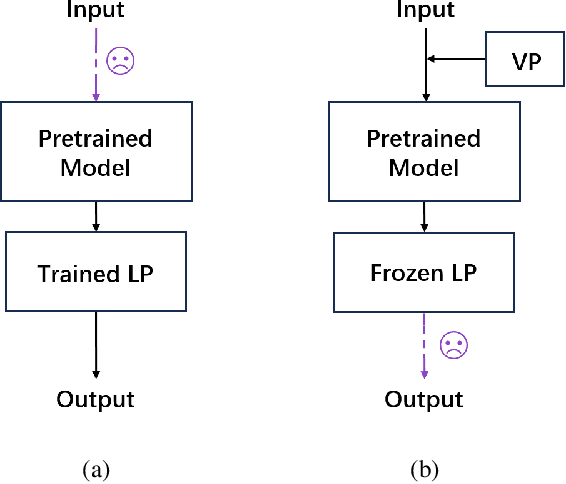
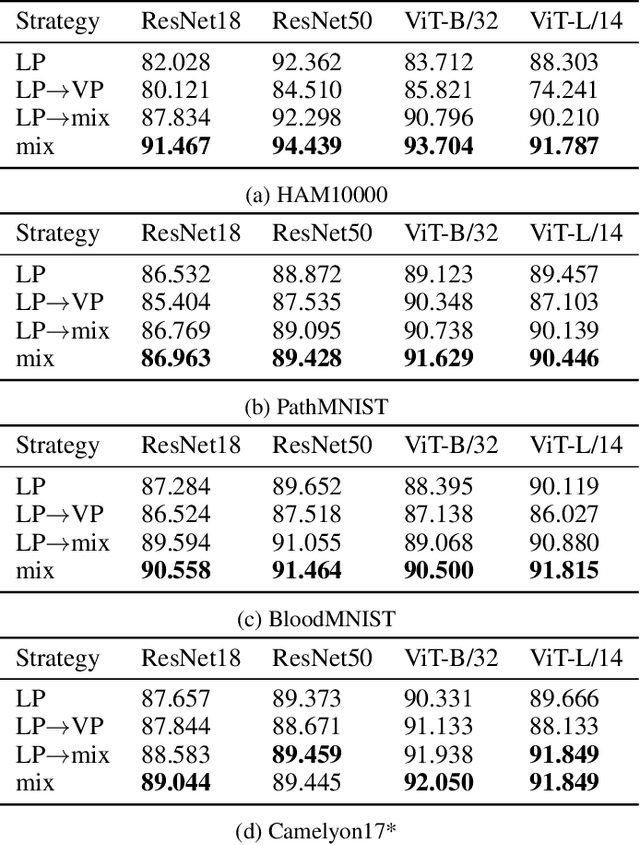
Medical images are often more difficult to acquire than natural images due to the specialism of the equipment and technology, which leads to less medical image datasets. So it is hard to train a strong pretrained medical vision model. How to make the best of natural pretrained vision model and adapt in medical domain still pends. For image classification, a popular method is linear probe (LP). However, LP only considers the output after feature extraction. Yet, there exists a gap between input medical images and natural pretrained vision model. We introduce visual prompting (VP) to fill in the gap, and analyze the strategies of coupling between LP and VP. We design a joint learning loss function containing categorisation loss and discrepancy loss, which describe the variance of prompted and plain images, naming this joint training strategy MoVL (Mixture of Visual Prompting and Linear Probe). We experiment on 4 medical image classification datasets, with two mainstream architectures, ResNet and CLIP. Results shows that without changing the parameters and architecture of backbone model and with less parameters, there is potential for MoVL to achieve full finetune (FF) accuracy (on four medical datasets, average 90.91% for MoVL and 91.13% for FF). On out of distribution medical dataset, our method(90.33%) can outperform FF (85.15%) with absolute 5.18 % lead.