 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSA-FedLora: Adaptive Parameter Allocation for Efficient Federated Learning with LoRA Tuning
Paper and Code
May 15, 2024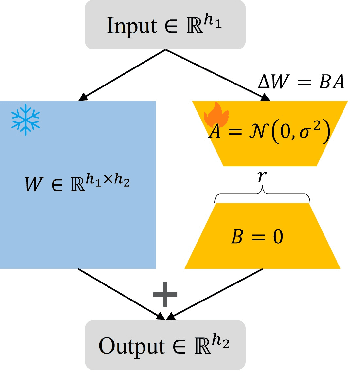

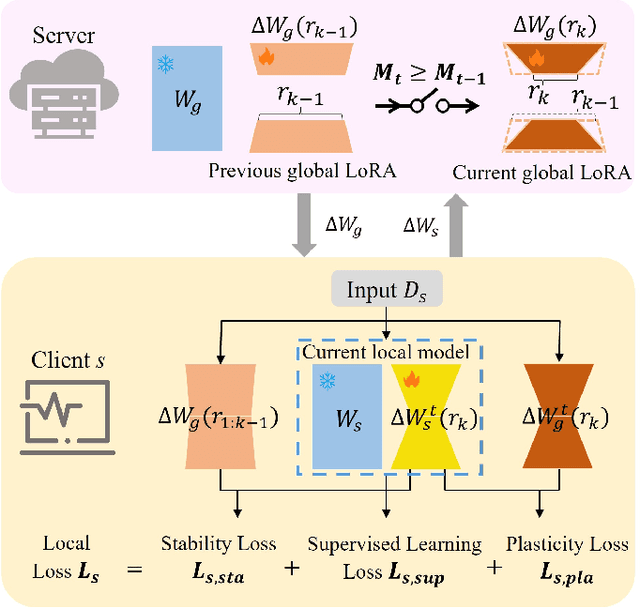

Fine-tuning large-scale pre-trained models via transfer learning is an emerging important paradigm for a wide range of downstream tasks, with performance heavily reliant on extensive data. Federated learning (FL), as a distributed framework, provides a secure solution to train models on local datasets while safeguarding raw sensitive data. However, FL networks encounter high communication costs due to the massive parameters of large-scale pre-trained models, necessitating parameter-efficient methods. Notably, parameter efficient fine tuning, such as Low-Rank Adaptation (LoRA), has shown remarkable success in fine-tuning pre-trained models. However, prior research indicates that the fixed parameter budget may be prone to the overfitting or slower convergence. To address this challenge, we propose a Simulated Annealing-based Federated Learning with LoRA tuning (SA-FedLoRA) approach by reducing trainable parameters. Specifically, SA-FedLoRA comprises two stages: initiating and annealing. (1) In the initiating stage, we implement a parameter regularization approach during the early rounds of aggregation, aiming to mitigate client drift and accelerate the convergence for the subsequent tuning. (2) In the annealing stage, we allocate higher parameter budget during the early 'heating' phase and then gradually shrink the budget until the 'cooling' phase. This strategy not only facilitates convergence to the global optimum but also reduces communication costs. Experimental results demonstrate that SA-FedLoRA is an efficient FL, achieving superior performance to FedAvg and significantly reducing communication parameters by up to 93.62%.