 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study on Information Extraction using Large Language Models
Sep 04, 2024
Human-like large language models (LLMs), especially the most powerful and popular ones in OpenAI's GPT family, have proven to be very helpful for many natural language processing (NLP) related tasks. Therefore, various attempts have been made to apply LLMs to information extraction (IE), which is a fundamental NLP task that involves extracting information from unstructured plain text. To demonstrate the latest representative progress in LLMs' information extraction ability, we assess the information extraction ability of GPT-4 (the latest version of GPT at the time of writing this paper) from four perspectives: Performance, Evaluation Criteria, Robustness, and Error Types. Our results suggest a visible performance gap between GPT-4 and state-of-the-art (SOTA) IE methods. To alleviate this problem, considering the LLMs' human-like characteristics, we propose and analyze the effects of a series of simple prompt-based methods, which can be generalized to other LLMs and NLP tasks. Rich experiments show our methods' effectiveness and some of their remaining issues in improving GPT-4's information extraction ability.
Is Information Extraction Solved by ChatGPT? An Analysis of Performance, Evaluation Criteria, Robustness and Errors
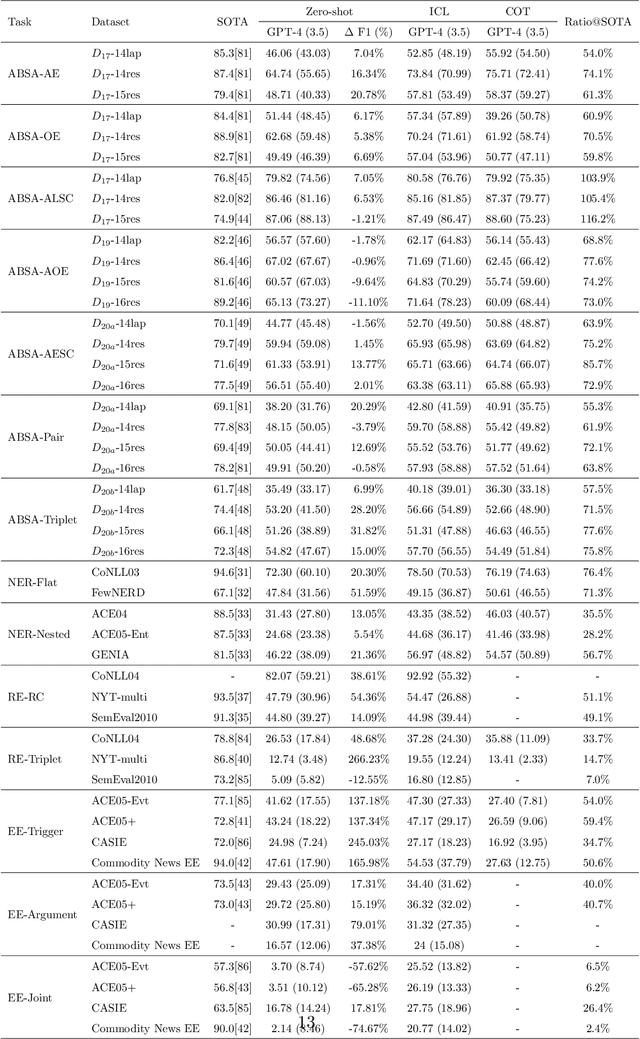
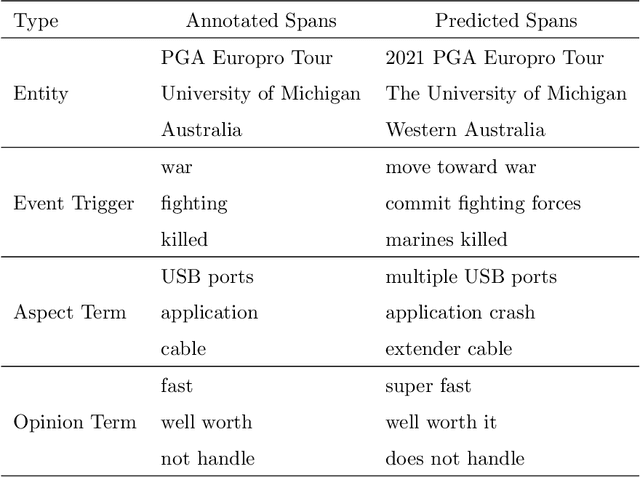
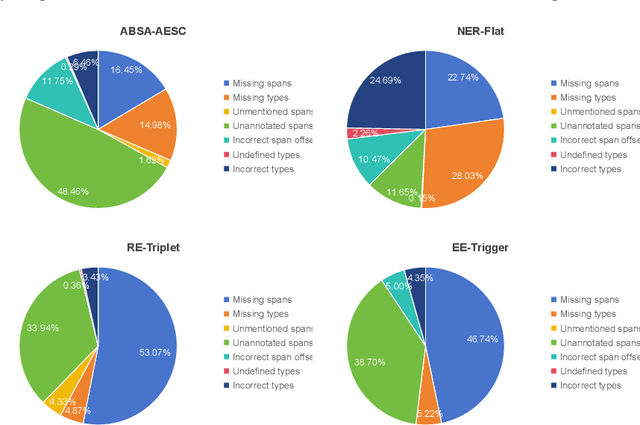
May 23, 2023ChatGPT has stimulated the research boom in the field of large language models. In this paper, we assess the capabilities of ChatGPT from four perspectives including Performance, Evaluation Criteria, Robustness and Error Types. Specifically, we first evaluate ChatGPT's performance on 17 datasets with 14 IE sub-tasks under the zero-shot, few-shot and chain-of-thought scenarios, and find a huge performance gap between ChatGPT and SOTA results. Next, we rethink this gap and propose a soft-matching strategy for evaluation to more accurately reflect ChatGPT's performance. Then, we analyze the robustness of ChatGPT on 14 IE sub-tasks, and find that: 1) ChatGPT rarely outputs invalid responses; 2) Irrelevant context and long-tail target types greatly affect ChatGPT's performance; 3) ChatGPT cannot understand well the subject-object relationships in RE task. Finally, we analyze the errors of ChatGPT, and find that "unannotated spans" is the most dominant error type. This raises concerns about the quality of annotated data, and indicates the possibility of annotating data with ChatGPT. The data and code are released at Github site.
Document-level Relation Extraction with Relation Correlations
Dec 20, 2022Document-level relation extraction faces two overlooked challenges: long-tail problem and multi-label problem. Previous work focuses mainly on obtaining better contextual representations for entity pairs, hardly address the above challenges. In this paper, we analyze the co-occurrence correlation of relations, and introduce it into DocRE task for the first time. We argue that the correlations can not only transfer knowledge between data-rich relations and data-scarce ones to assist in the training of tailed relations, but also reflect semantic distance guiding the classifier to identify semantically close relations for multi-label entity pairs. Specifically, we use relation embedding as a medium, and propose two co-occurrence prediction sub-tasks from both coarse- and fine-grained perspectives to capture relation correlations. Finally, the learned correlation-aware embeddings are used to guide the extraction of relational facts. Substantial experiments on two popular DocRE datasets are conducted, and our method achieves superior results compared to baselines. Insightful analysis also demonstrates the potential of relation correlations to address the above challenges.
Distantly Supervised Relation Extraction via Recursive Hierarchy-Interactive Attention and Entity-Order Perception
May 18, 2021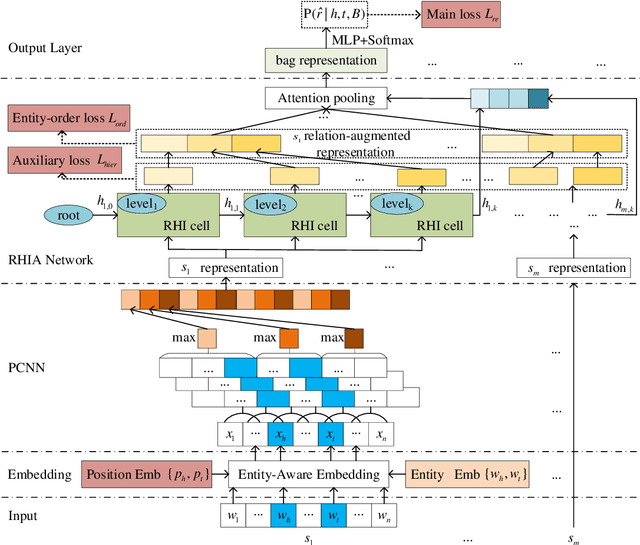
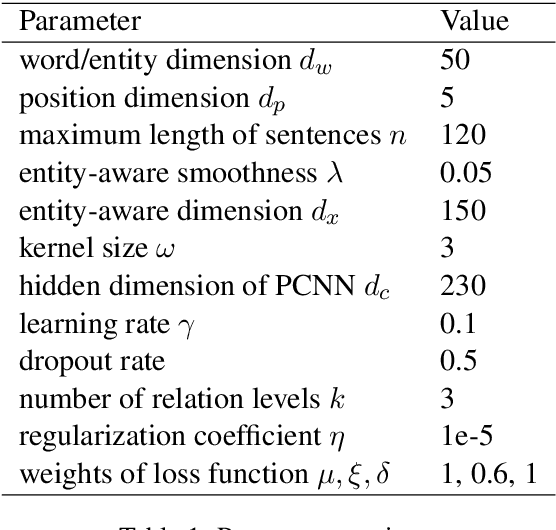
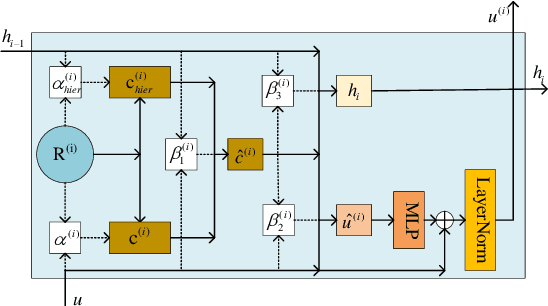

Distantly supervised relation extraction has drawn significant attention recently. However, almost all prior works ignore the fact that, in a sentence, the appearance order of two entities contributes to the understanding of its semantics. Furthermore, they leverage relation hierarchies but don't fully exploit the heuristic effect between relation levels, i.e., higher-level relations can give useful information to the lower ones. In this paper, we design a novel Recursive Hierarchy-Interactive Attention network (RHIA), which uses the hierarchical structure of the relation to model the interactive information between the relation levels to further handle long-tail relations. It generates relation-augmented sentence representations along hierarchical relation chains in a recursive structure. Besides, we introduce a newfangled training objective, called Entity-Order Perception (EOP), to make the sentence encoder retain more entity appearance information. Substantial experiments on the popular New York Times (NYT) dataset are conducted. Compared to prior baselines, our approach achieves state-of-the-art performance in terms of precision-recall (P-R) curves, AUC, Top-N precision and other evaluation metrics.