 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Word Embedding with Better Distance Weighting and Window Size Scheduling
Paper and Code
Apr 23, 2024
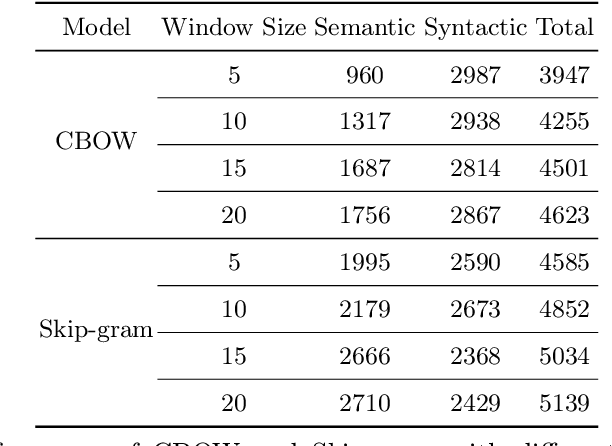


Distributed word representation (a.k.a. word embedding) is a key focus in natural language processing (NLP). As a highly successful word embedding model, Word2Vec offers an efficient method for learning distributed word representations on large datasets. However, Word2Vec lacks consideration for distances between center and context words. We propose two novel methods, Learnable Formulated Weights (LFW) and Epoch-based Dynamic Window Size (EDWS), to incorporate distance information into two variants of Word2Vec, the Continuous Bag-of-Words (CBOW) model and the Continuous Skip-gram (Skip-gram) model. For CBOW, LFW uses a formula with learnable parameters that best reflects the relationship of influence and distance between words to calculate distance-related weights for average pooling, providing insights for future NLP text modeling research. For Skip-gram, we improve its dynamic window size strategy to introduce distance information in a more balanced way. Experiments prove the effectiveness of LFW and EDWS in enhancing Word2Vec's performance, surpassing previous state-of-the-art methods.