 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Evolution Strategies with Multi-Level Learning for Large-Scale Black-Box Optimization
Paper and Code
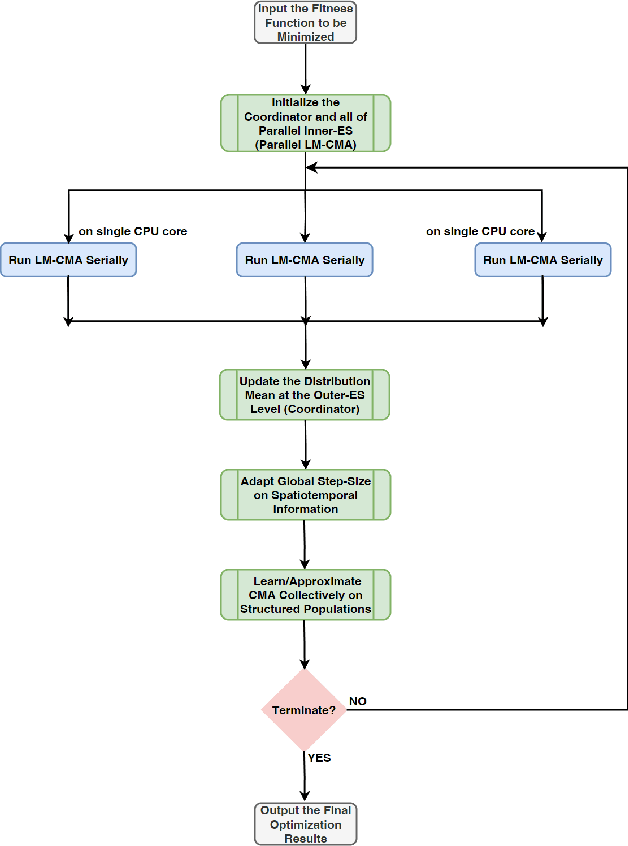
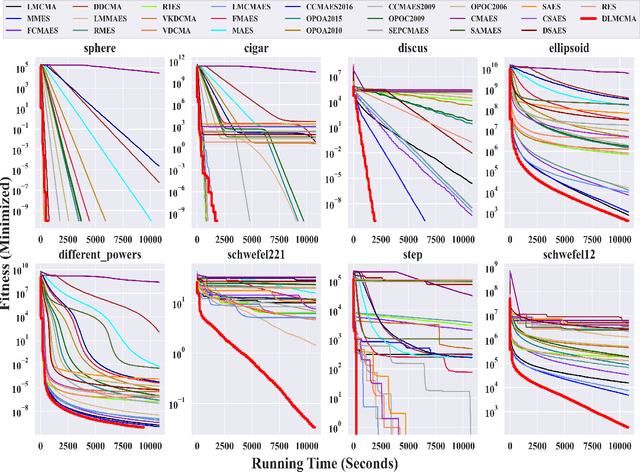
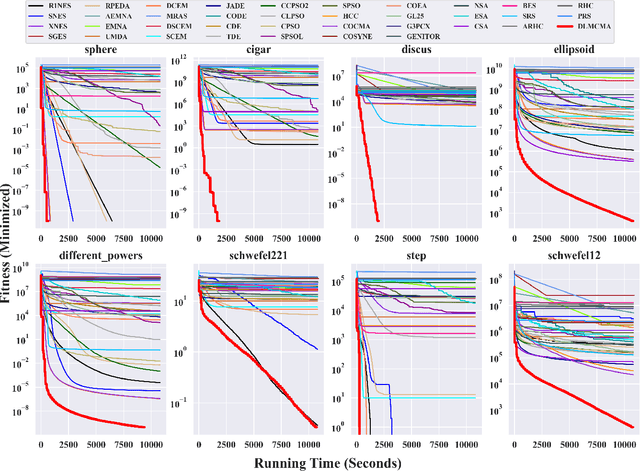

In the post-Moore era, the main performance gains of black-box optimizers are increasingly depending upon parallelism, especially for large-scale optimization (LSO). In this paper, we propose to parallelize the well-established covariance matrix adaptation evolution strategy (CMA-ES) and in particular its one latest variant called limited-memory CMA (LM-CMA) for LSO. To achieve scalability while maintaining the invariance property as much as possible, we present a multilevel learning-based meta-framework. Owing to its hierarchically organized structure, Meta-ES is well-suited to implement our distributed meta-framework, wherein the outer-ES controls strategy parameters while all parallel inner-ESs run the serial LM-CMA with different settings. For the distribution mean update of the outer-ES, both the elitist and multi-recombination strategy are used in parallel to avoid stagnation and regression, respectively. To exploit spatiotemporal information, the global step-size adaptation combines Meta-ES with the parallel cumulative step-size adaptation. After each isolation time, our meta-framework employs both the structure and parameter learning strategy to combine aligned evolution paths for CMA reconstruction. Experiments on a set of large-scale benchmarking functions with memory-intensive evaluations, arguably reflecting many data-driven optimization problems, validate the benefits (e.g., scalability w.r.t. CPU cores, effectiveness w.r.t. solution quality, and adaptability w.r.t. second-order learning) and costs of our meta-framework.