 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrelational Lagrangian Schrödinger Bridge: Learning Dynamics with Population-Level Regularization
Feb 04, 2024Accurate modeling of system dynamics holds intriguing potential in broad scientific fields including cytodynamics and fluid mechanics. This task often presents significant challenges when (i) observations are limited to cross-sectional samples (where individual trajectories are inaccessible for learning), and moreover, (ii) the behaviors of individual particles are heterogeneous (especially in biological systems due to biodiversity). To address them, we introduce a novel framework dubbed correlational Lagrangian Schr\"odinger bridge (CLSB), aiming to seek for the evolution "bridging" among cross-sectional observations, while regularized for the minimal population "cost". In contrast to prior methods relying on \textit{individual}-level regularizers for all particles \textit{homogeneously} (e.g. restraining individual motions), CLSB operates at the population level admitting the heterogeneity nature, resulting in a more generalizable modeling in practice. To this end, our contributions include (1) a new class of population regularizers capturing the temporal variations in multivariate relations, with the tractable formulation derived, (2) three domain-informed instantiations based on genetic co-expression stability, and (3) an integration of population regularizers into data-driven generative models as constrained optimization, and a numerical solution, with further extension to conditional generative models. Empirically, we demonstrate the superiority of CLSB in single-cell sequencing data analyses such as simulating cell development over time and predicting cellular responses to drugs of varied doses.
Augmentations in Hypergraph Contrastive Learning: Fabricated and Generative
Oct 07, 2022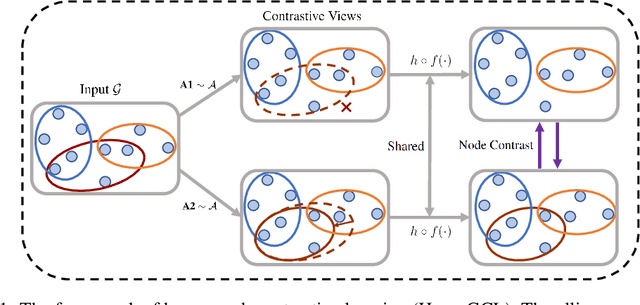

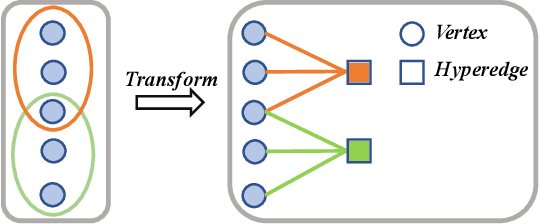

This paper targets at improving the generalizability of hypergraph neural networks in the low-label regime, through applying the contrastive learning approach from images/graphs (we refer to it as HyperGCL). We focus on the following question: How to construct contrastive views for hypergraphs via augmentations? We provide the solutions in two folds. First, guided by domain knowledge, we fabricate two schemes to augment hyperedges with higher-order relations encoded, and adopt three vertex augmentation strategies from graph-structured data. Second, in search of more effective views in a data-driven manner, we for the first time propose a hypergraph generative model to generate augmented views, and then an end-to-end differentiable pipeline to jointly learn hypergraph augmentations and model parameters. Our technical innovations are reflected in designing both fabricated and generative augmentations of hypergraphs. The experimental findings include: (i) Among fabricated augmentations in HyperGCL, augmenting hyperedges provides the most numerical gains, implying that higher-order information in structures is usually more downstream-relevant; (ii) Generative augmentations do better in preserving higher-order information to further benefit generalizability; (iii) HyperGCL also boosts robustness and fairness in hypergraph representation learning. Codes are released at https://github.com/weitianxin/HyperGCL.
Bringing Your Own View: Graph Contrastive Learning without Prefabricated Data Augmentations
Jan 04, 2022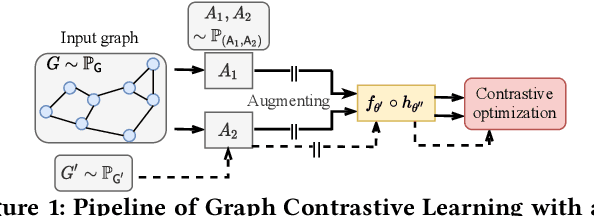

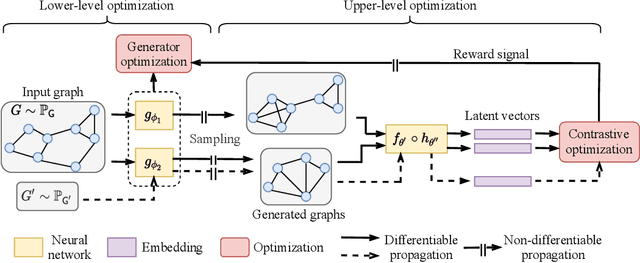
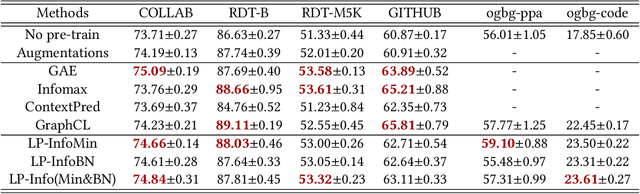
Self-supervision is recently surging at its new frontier of graph learning. It facilitates graph representations beneficial to downstream tasks; but its success could hinge on domain knowledge for handcraft or the often expensive trials and errors. Even its state-of-the-art representative, graph contrastive learning (GraphCL), is not completely free of those needs as GraphCL uses a prefabricated prior reflected by the ad-hoc manual selection of graph data augmentations. Our work aims at advancing GraphCL by answering the following questions: How to represent the space of graph augmented views? What principle can be relied upon to learn a prior in that space? And what framework can be constructed to learn the prior in tandem with contrastive learning? Accordingly, we have extended the prefabricated discrete prior in the augmentation set, to a learnable continuous prior in the parameter space of graph generators, assuming that graph priors per se, similar to the concept of image manifolds, can be learned by data generation. Furthermore, to form contrastive views without collapsing to trivial solutions due to the prior learnability, we have leveraged both principles of information minimization (InfoMin) and information bottleneck (InfoBN) to regularize the learned priors. Eventually, contrastive learning, InfoMin, and InfoBN are incorporated organically into one framework of bi-level optimization. Our principled and automated approach has proven to be competitive against the state-of-the-art graph self-supervision methods, including GraphCL, on benchmarks of small graphs; and shown even better generalizability on large-scale graphs, without resorting to human expertise or downstream validation. Our code is publicly released at https://github.com/Shen-Lab/GraphCL_Automated.
Graph Contrastive Learning Automated
Jun 28, 2021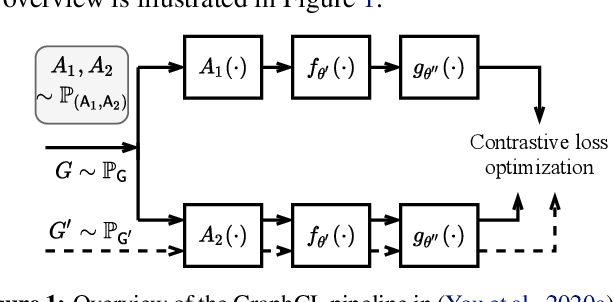
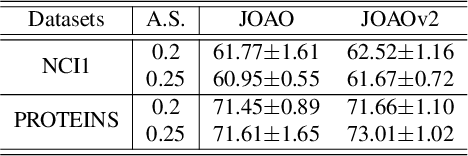
Self-supervised learning on graph-structured data has drawn recent interest for learning generalizable, transferable and robust representations from unlabeled graphs. Among many, graph contrastive learning (GraphCL) has emerged with promising representation learning performance. Unfortunately, unlike its counterpart on image data, the effectiveness of GraphCL hinges on ad-hoc data augmentations, which have to be manually picked per dataset, by either rules of thumb or trial-and-errors, owing to the diverse nature of graph data. That significantly limits the more general applicability of GraphCL. Aiming to fill in this crucial gap, this paper proposes a unified bi-level optimization framework to automatically, adaptively and dynamically select data augmentations when performing GraphCL on specific graph data. The general framework, dubbed JOint Augmentation Optimization (JOAO), is instantiated as min-max optimization. The selections of augmentations made by JOAO are shown to be in general aligned with previous "best practices" observed from handcrafted tuning: yet now being automated, more flexible and versatile. Moreover, we propose a new augmentation-aware projection head mechanism, which will route output features through different projection heads corresponding to different augmentations chosen at each training step. Extensive experiments demonstrate that JOAO performs on par with or sometimes better than the state-of-the-art competitors including GraphCL, on multiple graph datasets of various scales and types, yet without resorting to any laborious dataset-specific tuning on augmentation selection. We release the code at https://github.com/Shen-Lab/GraphCL_Automated.
Cross-Modality Protein Embedding for Compound-Protein Affinity and Contact Prediction
Nov 14, 2020Compound-protein pairs dominate FDA-approved drug-target pairs and the prediction of compound-protein affinity and contact (CPAC) could help accelerate drug discovery. In this study we consider proteins as multi-modal data including 1D amino-acid sequences and (sequence-predicted) 2D residue-pair contact maps. We empirically evaluate the embeddings of the two single modalities in their accuracy and generalizability of CPAC prediction (i.e. structure-free interpretable compound-protein affinity prediction). And we rationalize their performances in both challenges of embedding individual modalities and learning generalizable embedding-label relationship. We further propose two models involving cross-modality protein embedding and establish that the one with cross interaction (thus capturing correlations among modalities) outperforms SOTAs and our single modality models in affinity, contact, and binding-site predictions for proteins never seen in the training set.
Graph Contrastive Learning with Augmentations
Nov 11, 2020
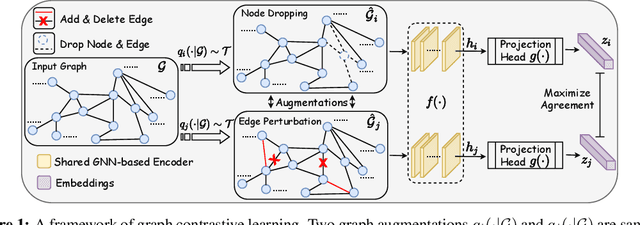

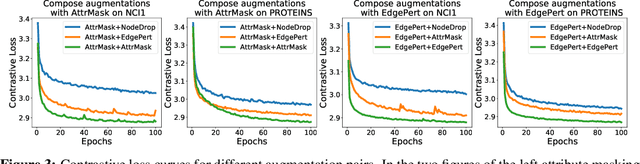
Generalizable, transferrable, and robust representation learning on graph-structured data remains a challenge for current graph neural networks (GNNs). Unlike what has been developed for convolutional neural networks (CNNs) for image data, self-supervised learning and pre-training are less explored for GNNs. In this paper, we propose a graph contrastive learning (GraphCL) framework for learning unsupervised representations of graph data. We first design four types of graph augmentations to incorporate various priors. We then systematically study the impact of various combinations of graph augmentations on multiple datasets, in four different settings: semi-supervised, unsupervised, and transfer learning as well as adversarial attacks. The results show that, even without tuning augmentation extents nor using sophisticated GNN architectures, our GraphCL framework can produce graph representations of similar or better generalizability, transferrability, and robustness compared to state-of-the-art methods. We also investigate the impact of parameterized graph augmentation extents and patterns, and observe further performance gains in preliminary experiments. Our codes are available at https://github.com/Shen-Lab/GraphCL.
When Does Self-Supervision Help Graph Convolutional Networks?
Jul 04, 2020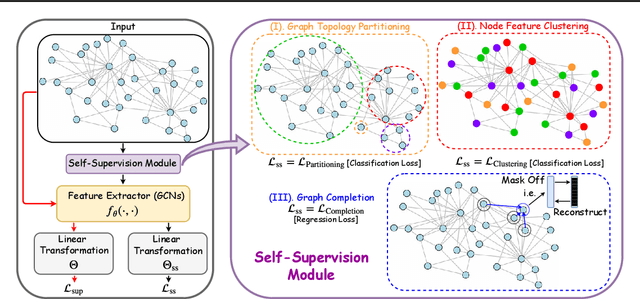
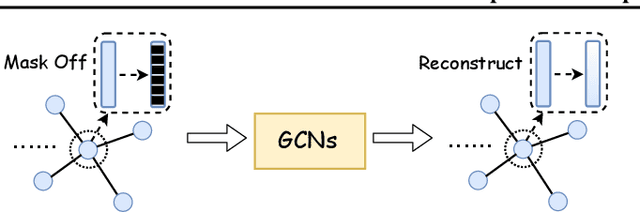

Self-supervision as an emerging technique has been employed to train convolutional neural networks (CNNs) for more transferrable, generalizable, and robust representation learning of images. Its introduction to graph convolutional networks (GCNs) operating on graph data is however rarely explored. In this study, we report the first systematic exploration and assessment of incorporating self-supervision into GCNs. We first elaborate three mechanisms to incorporate self-supervision into GCNs, analyze the limitations of pretraining & finetuning and self-training, and proceed to focus on multi-task learning. Moreover, we propose to investigate three novel self-supervised learning tasks for GCNs with theoretical rationales and numerical comparisons. Lastly, we further integrate multi-task self-supervision into graph adversarial training. Our results show that, with properly designed task forms and incorporation mechanisms, self-supervision benefits GCNs in gaining more generalizability and robustness. Our codes are available at https://github.com/Shen-Lab/SS-GCNs.
L^2-GCN: Layer-Wise and Learned Efficient Training of Graph Convolutional Networks
Apr 22, 2020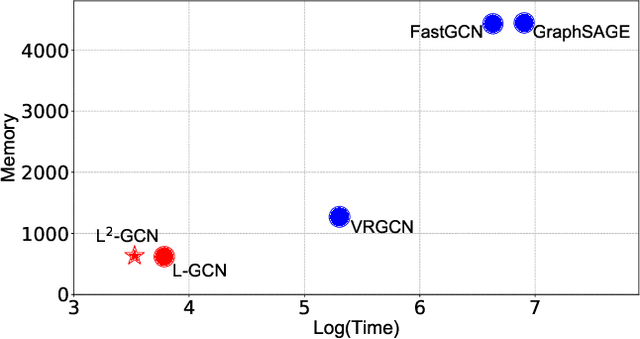

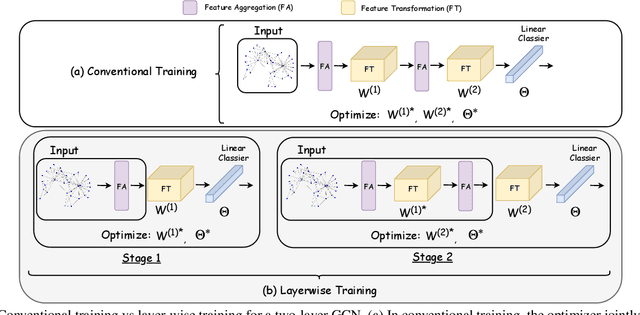
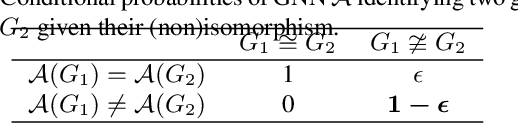
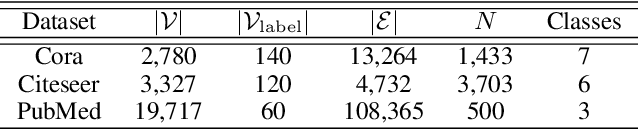
Graph convolution networks (GCN) are increasingly popular in many applications, yet remain notoriously hard to train over large graph datasets. They need to compute node representations recursively from their neighbors. Current GCN training algorithms suffer from either high computational costs that grow exponentially with the number of layers, or high memory usage for loading the entire graph and node embeddings. In this paper, we propose a novel efficient layer-wise training framework for GCN (L-GCN), that disentangles feature aggregation and feature transformation during training, hence greatly reducing time and memory complexities. We present theoretical analysis for L-GCN under the graph isomorphism framework, that L-GCN leads to as powerful GCNs as the more costly conventional training algorithm does, under mild conditions. We further propose L^2-GCN, which learns a controller for each layer that can automatically adjust the training epochs per layer in L-GCN. Experiments show that L-GCN is faster than state-of-the-arts by at least an order of magnitude, with a consistent of memory usage not dependent on dataset size, while maintaining comparable prediction performance. With the learned controller, L^2-GCN can further cut the training time in half. Our codes are available at https://github.com/Shen-Lab/L2-GCN and supplementary materials at https://slack-files.com/TC7R2EBMJ-F012C60T335-281aabd097.