 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL^2-GCN: Layer-Wise and Learned Efficient Training of Graph Convolutional Networks
Paper and Code
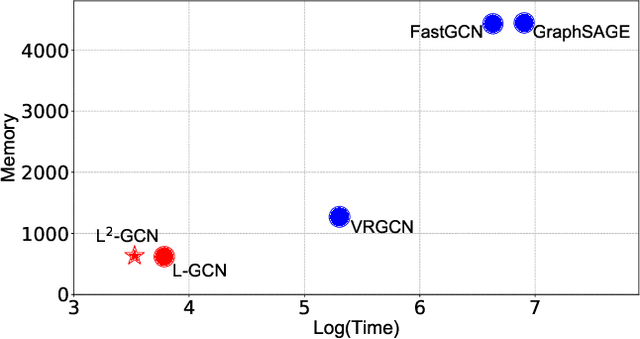

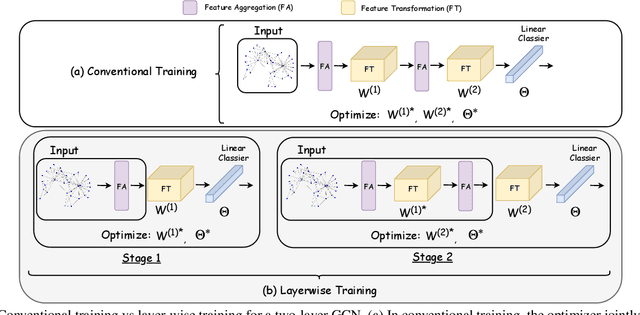
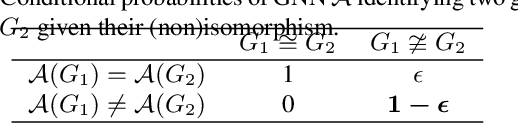
Graph convolution networks (GCN) are increasingly popular in many applications, yet remain notoriously hard to train over large graph datasets. They need to compute node representations recursively from their neighbors. Current GCN training algorithms suffer from either high computational costs that grow exponentially with the number of layers, or high memory usage for loading the entire graph and node embeddings. In this paper, we propose a novel efficient layer-wise training framework for GCN (L-GCN), that disentangles feature aggregation and feature transformation during training, hence greatly reducing time and memory complexities. We present theoretical analysis for L-GCN under the graph isomorphism framework, that L-GCN leads to as powerful GCNs as the more costly conventional training algorithm does, under mild conditions. We further propose L^2-GCN, which learns a controller for each layer that can automatically adjust the training epochs per layer in L-GCN. Experiments show that L-GCN is faster than state-of-the-arts by at least an order of magnitude, with a consistent of memory usage not dependent on dataset size, while maintaining comparable prediction performance. With the learned controller, L^2-GCN can further cut the training time in half. Our codes are available at https://github.com/Shen-Lab/L2-GCN and supplementary materials at https://slack-files.com/TC7R2EBMJ-F012C60T335-281aabd097.