 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Parameter Learning and Bi-Clustering for Multi-Response Models
Paper and Code
Apr 29, 2018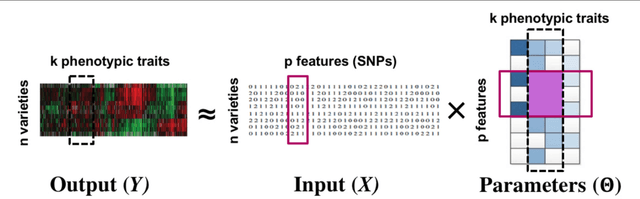
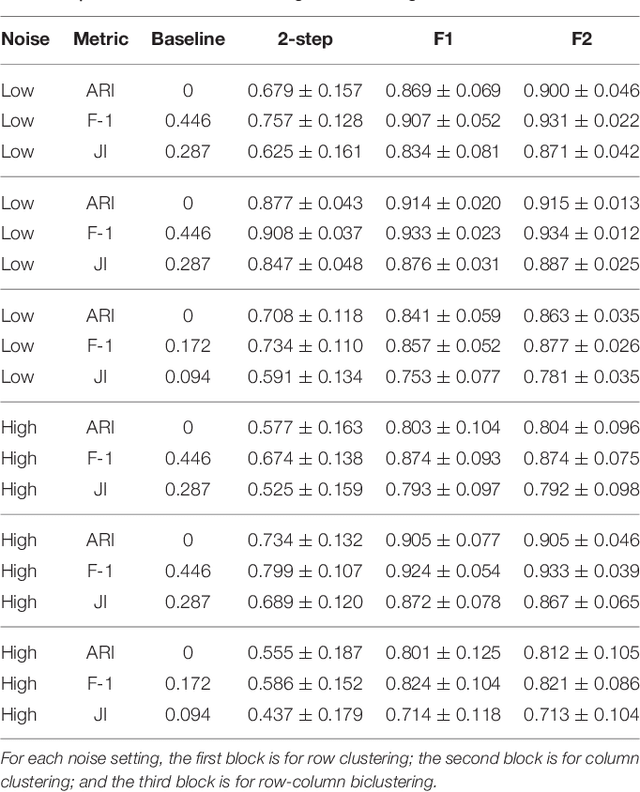

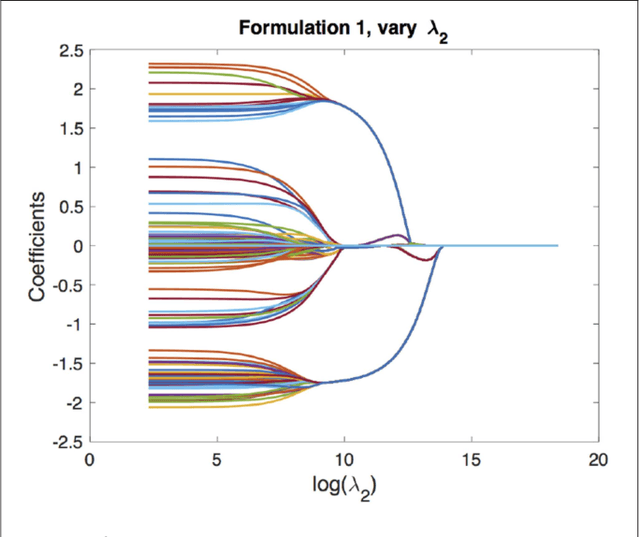
We consider multi-response and multitask regression models, where the parameter matrix to be estimated is expected to have an unknown grouping structure. The groupings can be along tasks, or features, or both, the last one indicating a bi-cluster or "checkerboard" structure. Discovering this grouping structure along with parameter inference makes sense in several applications, such as multi-response Genome-Wide Association Studies. This additional structure can not only can be leveraged for more accurate parameter estimation, but it also provides valuable information on the underlying data mechanisms (e.g. relationships among genotypes and phenotypes in GWAS). In this paper, we propose two formulations to simultaneously learn the parameter matrix and its group structures, based on convex regularization penalties. We present optimization approaches to solve the resulting problems and provide numerical convergence guarantees. Our approaches are validated on extensive simulations and real datasets concerning phenotypes and genotypes of plant varieties.