 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMin-Max Bilevel Multi-objective Optimization with Applications in Machine Learning
Mar 03, 2022
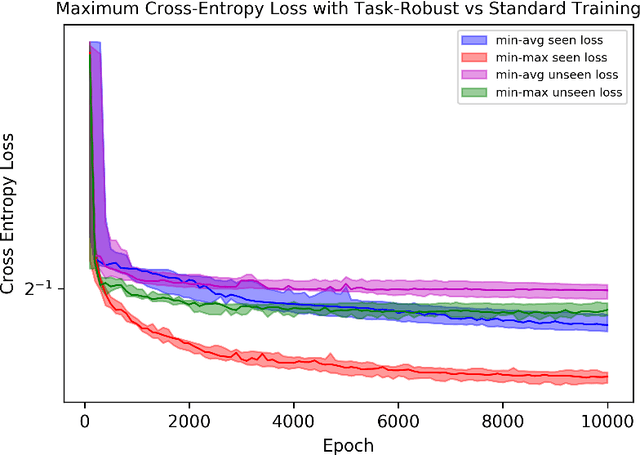
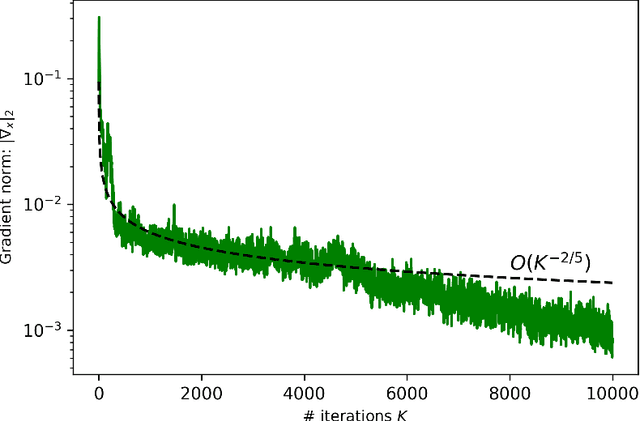
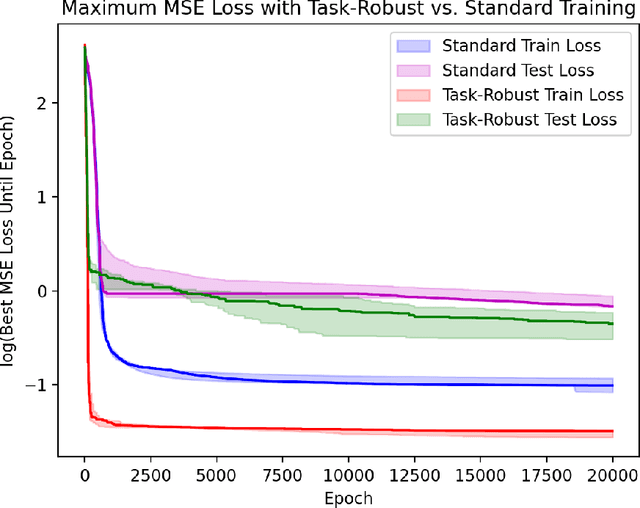
This paper is the first to propose a generic min-max bilevel multi-objective optimization framework, highlighting applications in representation learning and hyperparameter optimization. In many machine learning applications such as meta-learning, multi-task learning, and representation learning, a subset of the parameters are shared by all the tasks, while each specific task has its own set of additional parameters. By leveraging the recent advances of nonconvex min-max optimization, we propose a gradient descent-ascent bilevel optimization (MORBiT) algorithm which is able to extract a set of shared parameters that is robust over all tasks and further overcomes the distributional shift between training and testing tasks. Theoretical analyses show that MORBiT converges to the first-order stationary point at a rate of $\mathcal{O}(\sqrt{n}K^{-2/5})$ for a class of nonconvex problems, where $K$ denotes the total number of iterations and $n$ denotes the number of tasks. Overall, we formulate a min-max bilevel multi-objective optimization problem, provide a single loop two-timescale algorithm with convergence rate guarantees, and show theoretical bounds on the generalization abilities of the optimizer. Experimental results on sinusoid regression and representation learning showcase the superiority of MORBiT over state-of-the-art methods, validating our convergence and generalization results.
Revisiting Contrastive Learning through the Lens of Neighborhood Component Analysis: an Integrated Framework
Dec 08, 2021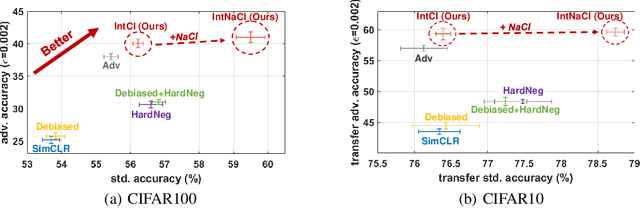
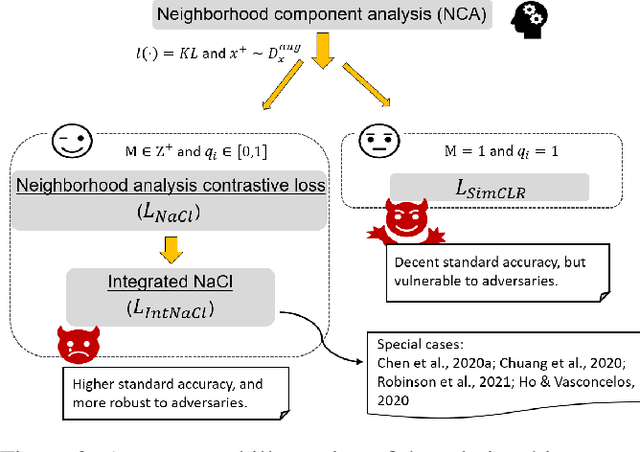
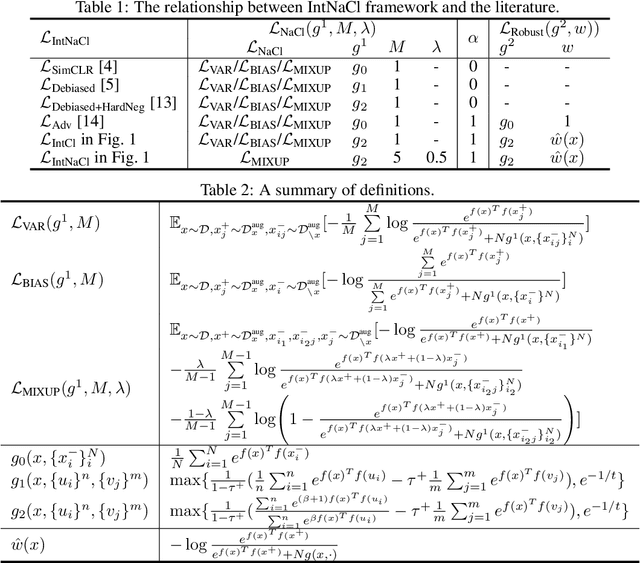
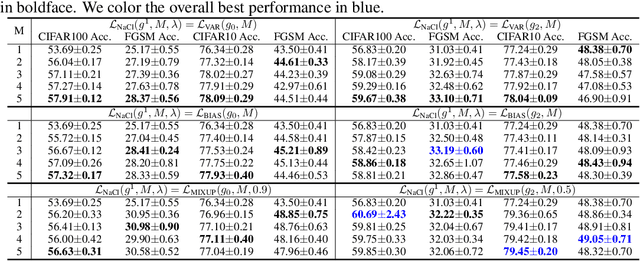
As a seminal tool in self-supervised representation learning, contrastive learning has gained unprecedented attention in recent years. In essence, contrastive learning aims to leverage pairs of positive and negative samples for representation learning, which relates to exploiting neighborhood information in a feature space. By investigating the connection between contrastive learning and neighborhood component analysis (NCA), we provide a novel stochastic nearest neighbor viewpoint of contrastive learning and subsequently propose a series of contrastive losses that outperform the existing ones. Under our proposed framework, we show a new methodology to design integrated contrastive losses that could simultaneously achieve good accuracy and robustness on downstream tasks. With the integrated framework, we achieve up to 6\% improvement on the standard accuracy and 17\% improvement on the adversarial accuracy.