 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynBench: Task-Agnostic Benchmarking of Pretrained Representations using Synthetic Data
Oct 07, 2022
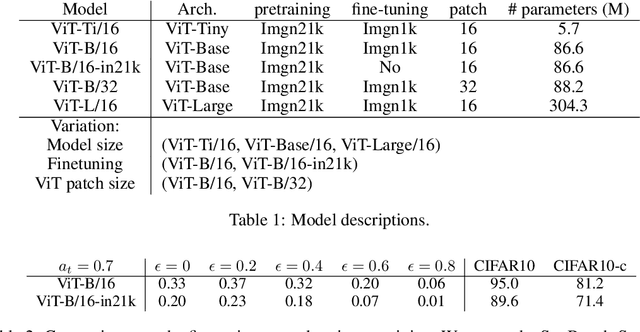


Recent success in fine-tuning large models, that are pretrained on broad data at scale, on downstream tasks has led to a significant paradigm shift in deep learning, from task-centric model design to task-agnostic representation learning and task-specific fine-tuning. As the representations of pretrained models are used as a foundation for different downstream tasks, this paper proposes a new task-agnostic framework, \textit{SynBench}, to measure the quality of pretrained representations using synthetic data. We set up a reference by a theoretically-derived robustness-accuracy tradeoff of the class conditional Gaussian mixture. Given a pretrained model, the representations of data synthesized from the Gaussian mixture are used to compare with our reference to infer the quality. By comparing the ratio of area-under-curve between the raw data and their representations, SynBench offers a quantifiable score for robustness-accuracy performance benchmarking. Our framework applies to a wide range of pretrained models taking continuous data inputs and is independent of the downstream tasks and datasets. Evaluated with several pretrained vision transformer models, the experimental results show that our SynBench score well matches the actual linear probing performance of the pre-trained model when fine-tuned on downstream tasks. Moreover, our framework can be used to inform the design of robust linear probing on pretrained representations to mitigate the robustness-accuracy tradeoff in downstream tasks.
Revisiting Contrastive Learning through the Lens of Neighborhood Component Analysis: an Integrated Framework
Dec 08, 2021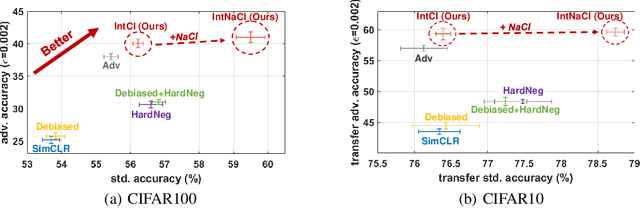
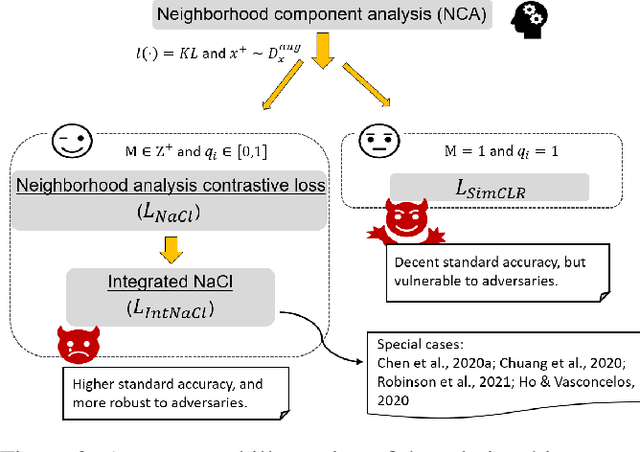
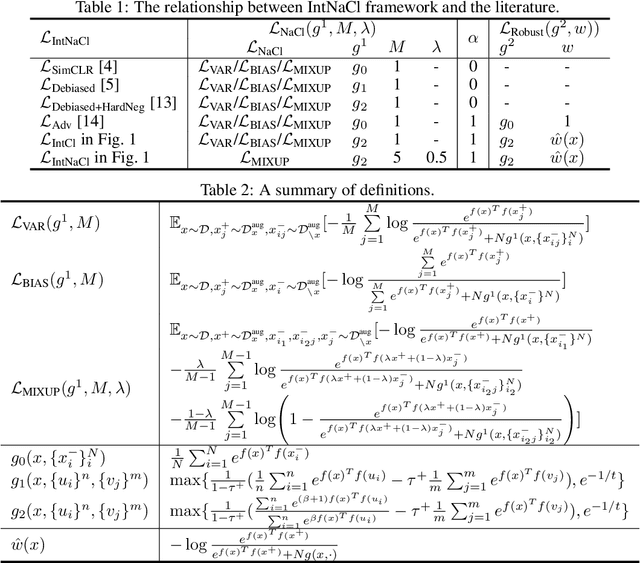
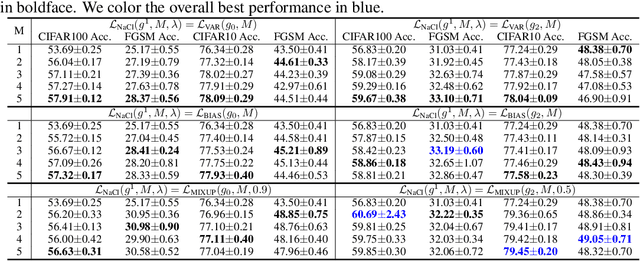
As a seminal tool in self-supervised representation learning, contrastive learning has gained unprecedented attention in recent years. In essence, contrastive learning aims to leverage pairs of positive and negative samples for representation learning, which relates to exploiting neighborhood information in a feature space. By investigating the connection between contrastive learning and neighborhood component analysis (NCA), we provide a novel stochastic nearest neighbor viewpoint of contrastive learning and subsequently propose a series of contrastive losses that outperform the existing ones. Under our proposed framework, we show a new methodology to design integrated contrastive losses that could simultaneously achieve good accuracy and robustness on downstream tasks. With the integrated framework, we achieve up to 6\% improvement on the standard accuracy and 17\% improvement on the adversarial accuracy.
Higher-Order Certification for Randomized Smoothing
Oct 13, 2020
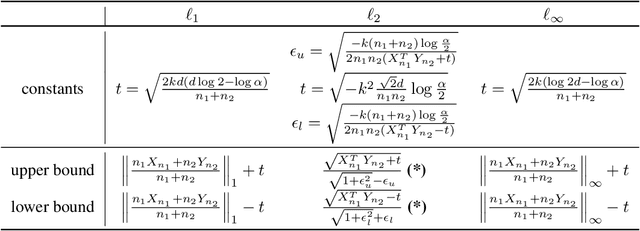


Randomized smoothing is a recently proposed defense against adversarial attacks that has achieved SOTA provable robustness against $\ell_2$ perturbations. A number of publications have extended the guarantees to other metrics, such as $\ell_1$ or $\ell_\infty$, by using different smoothing measures. Although the current framework has been shown to yield near-optimal $\ell_p$ radii, the total safety region certified by the current framework can be arbitrarily small compared to the optimal. In this work, we propose a framework to improve the certified safety region for these smoothed classifiers without changing the underlying smoothing scheme. The theoretical contributions are as follows: 1) We generalize the certification for randomized smoothing by reformulating certified radius calculation as a nested optimization problem over a class of functions. 2) We provide a method to calculate the certified safety region using $0^{th}$-order and $1^{st}$-order information for Gaussian-smoothed classifiers. We also provide a framework that generalizes the calculation for certification using higher-order information. 3) We design efficient, high-confidence estimators for the relevant statistics of the first-order information. Combining the theoretical contribution 2) and 3) allows us to certify safety region that are significantly larger than the ones provided by the current methods. On CIFAR10 and Imagenet datasets, the new regions certified by our approach achieve significant improvements on general $\ell_1$ certified radii and on the $\ell_2$ certified radii for color-space attacks ($\ell_2$ restricted to 1 channel) while also achieving smaller improvements on the general $\ell_2$ certified radii. Our framework can also provide a way to circumvent the current impossibility results on achieving higher magnitude of certified radii without requiring the use of data-dependent smoothing techniques.
Rethinking Randomized Smoothing for Adversarial Robustness
Mar 02, 2020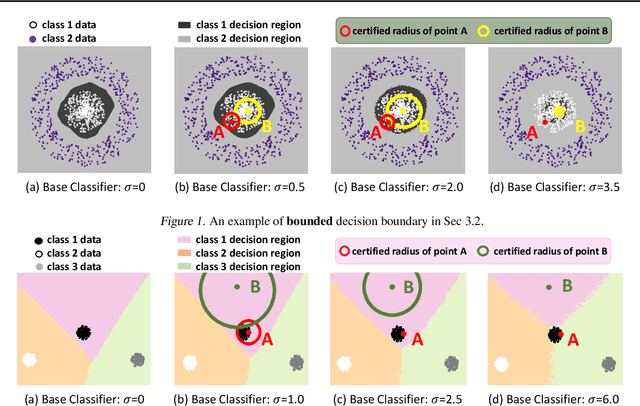



The fragility of modern machine learning models has drawn a considerable amount of attention from both academia and the public. While immense interests were in either crafting adversarial attacks as a way to measure the robustness of neural networks or devising worst-case analytical robustness verification with guarantees, few methods could enjoy both scalability and robustness guarantees at the same time. As an alternative to these attempts, randomized smoothing adopts a different prediction rule that enables statistical robustness arguments and can scale to large networks. However, in this paper, we point out for the first time the side effects of current randomized smoothing workflows. Specifically, we articulate and prove two major points: 1) the decision boundaries shrink with the adoption of randomized smoothing prediction rule; 2) noise augmentation does not necessarily resolve the shrinking issue and can even create additional issues.
Towards Verifying Robustness of Neural Networks Against Semantic Perturbations
Dec 19, 2019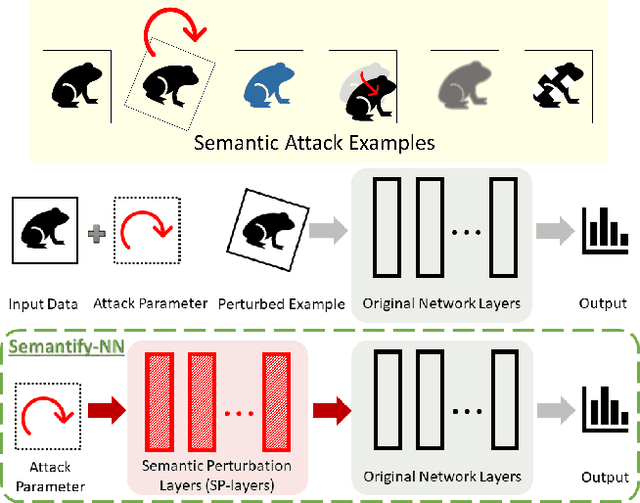

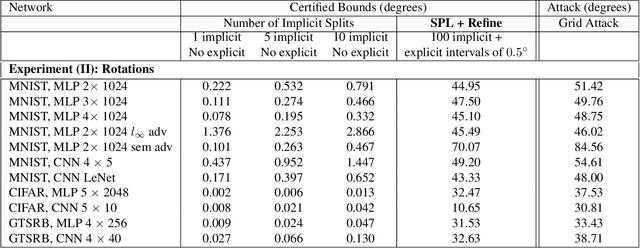

Verifying robustness of neural networks given a specified threat model is a fundamental yet challenging task. While current verification methods mainly focus on the L_p-norm-ball threat model of the input instances, robustness verification against semantic adversarial attacks inducing large L_p-norm perturbations such as color shifting and lighting adjustment are beyond their capacity. To bridge this gap, we propose Semantify-NN, a model-agnostic and generic robustness verification approach against semantic perturbations for neural networks. By simply inserting our proposed semantic perturbation layers (SP-layers) to the input layer of any given model, Semantify-NN is model-agnostic, and any $L_p$-norm-ball based verification tools can be used to verify the model robustness against semantic perturbations. We illustrate the principles of designing the SP-layers and provide examples including semantic perturbations to image classification in the space of hue, saturation, lightness, brightness, contrast and rotation, respectively. Experimental results on various network architectures and different datasets demonstrate the superior verification performance of Semantify-NN over L_p-norm-based verification frameworks that naively convert semantic perturbation to L_p-norm. To the best of our knowledge, Semantify-NN is the first framework to support robustness verification against a wide range of semantic perturbations.