 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Randomized Smoothing for Adversarial Robustness
Paper and Code
Mar 02, 2020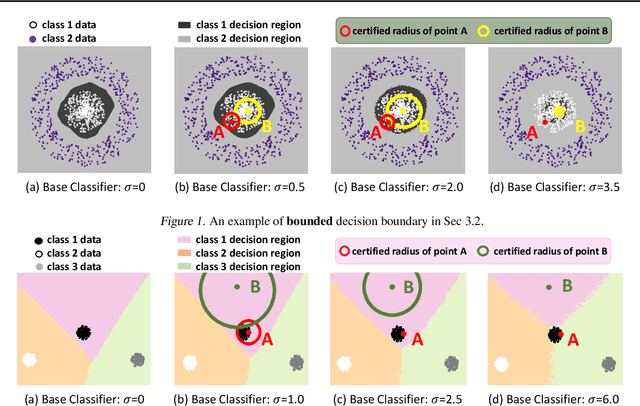



The fragility of modern machine learning models has drawn a considerable amount of attention from both academia and the public. While immense interests were in either crafting adversarial attacks as a way to measure the robustness of neural networks or devising worst-case analytical robustness verification with guarantees, few methods could enjoy both scalability and robustness guarantees at the same time. As an alternative to these attempts, randomized smoothing adopts a different prediction rule that enables statistical robustness arguments and can scale to large networks. However, in this paper, we point out for the first time the side effects of current randomized smoothing workflows. Specifically, we articulate and prove two major points: 1) the decision boundaries shrink with the adoption of randomized smoothing prediction rule; 2) noise augmentation does not necessarily resolve the shrinking issue and can even create additional issues.