 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Verifying Robustness of Neural Networks Against Semantic Perturbations
Paper and Code
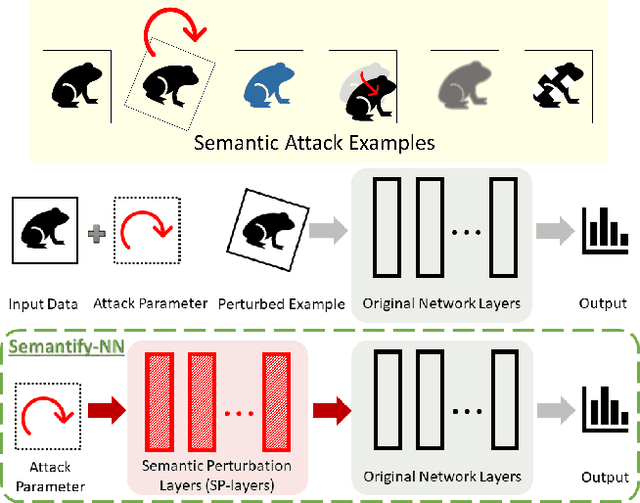

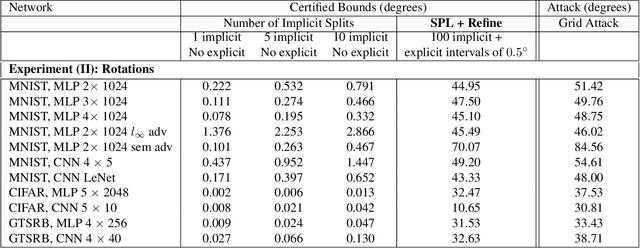

Verifying robustness of neural networks given a specified threat model is a fundamental yet challenging task. While current verification methods mainly focus on the L_p-norm-ball threat model of the input instances, robustness verification against semantic adversarial attacks inducing large L_p-norm perturbations such as color shifting and lighting adjustment are beyond their capacity. To bridge this gap, we propose Semantify-NN, a model-agnostic and generic robustness verification approach against semantic perturbations for neural networks. By simply inserting our proposed semantic perturbation layers (SP-layers) to the input layer of any given model, Semantify-NN is model-agnostic, and any $L_p$-norm-ball based verification tools can be used to verify the model robustness against semantic perturbations. We illustrate the principles of designing the SP-layers and provide examples including semantic perturbations to image classification in the space of hue, saturation, lightness, brightness, contrast and rotation, respectively. Experimental results on various network architectures and different datasets demonstrate the superior verification performance of Semantify-NN over L_p-norm-based verification frameworks that naively convert semantic perturbation to L_p-norm. To the best of our knowledge, Semantify-NN is the first framework to support robustness verification against a wide range of semantic perturbations.