 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models are Causal Knowledge Extractors for Zero-shot Video Question Answering
Paper and Code


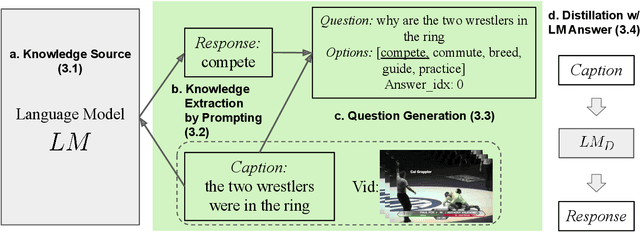

Causal Video Question Answering (CVidQA) queries not only association or temporal relations but also causal relations in a video. Existing question synthesis methods pre-trained question generation (QG) systems on reading comprehension datasets with text descriptions as inputs. However, QG models only learn to ask association questions (e.g., ``what is someone doing...'') and result in inferior performance due to the poor transfer of association knowledge to CVidQA, which focuses on causal questions like ``why is someone doing ...''. Observing this, we proposed to exploit causal knowledge to generate question-answer pairs, and proposed a novel framework, Causal Knowledge Extraction from Language Models (CaKE-LM), leveraging causal commonsense knowledge from language models to tackle CVidQA. To extract knowledge from LMs, CaKE-LM generates causal questions containing two events with one triggering another (e.g., ``score a goal'' triggers ``soccer player kicking ball'') by prompting LM with the action (soccer player kicking ball) to retrieve the intention (to score a goal). CaKE-LM significantly outperforms conventional methods by 4% to 6% of zero-shot CVidQA accuracy on NExT-QA and Causal-VidQA datasets. We also conduct comprehensive analyses and provide key findings for future research.