 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnforcing Reasoning in Visual Commonsense Reasoning
Oct 21, 2019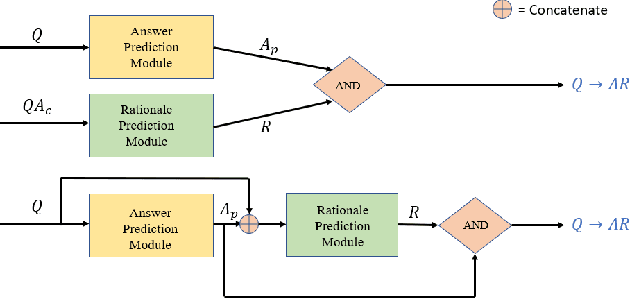
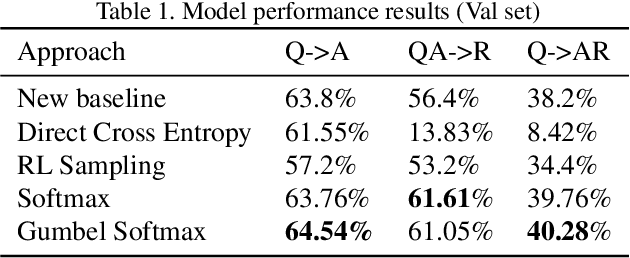


The task of Visual Commonsense Reasoning is extremely challenging in the sense that the model has to not only be able to answer a question given an image, but also be able to learn to reason. The baselines introduced in this task are quite limiting because two networks are trained for predicting answers and rationales separately. Question and image is used as input to train answer prediction network while question, image and correct answer are used as input in the rationale prediction network. As rationale is conditioned on the correct answer, it is based on the assumption that we can solve Visual Question Answering task without any error - which is over ambitious. Moreover, such an approach makes both answer and rationale prediction two completely independent VQA tasks rendering cognition task meaningless. In this paper, we seek to address these issues by proposing an end-to-end trainable model which considers both answers and their reasons jointly. Specifically, we first predict the answer for the question and then use the chosen answer to predict the rationale. However, a trivial design of such a model becomes non-differentiable which makes it difficult to train. We solve this issue by proposing four approaches - softmax, gumbel-softmax, reinforcement learning based sampling and direct cross entropy against all pairs of answers and rationales. We demonstrate through experiments that our model performs competitively against current state-of-the-art. We conclude with an analysis of presented approaches and discuss avenues for further work.