 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs as In-Context Meta-Learners for Model and Hyperparameter Selection
Oct 30, 2025



Model and hyperparameter selection are critical but challenging in machine learning, typically requiring expert intuition or expensive automated search. We investigate whether large language models (LLMs) can act as in-context meta-learners for this task. By converting each dataset into interpretable metadata, we prompt an LLM to recommend both model families and hyperparameters. We study two prompting strategies: (1) a zero-shot mode relying solely on pretrained knowledge, and (2) a meta-informed mode augmented with examples of models and their performance on past tasks. Across synthetic and real-world benchmarks, we show that LLMs can exploit dataset metadata to recommend competitive models and hyperparameters without search, and that improvements from meta-informed prompting demonstrate their capacity for in-context meta-learning. These results highlight a promising new role for LLMs as lightweight, general-purpose assistants for model selection and hyperparameter optimization.
When LLMs Play the Telephone Game: Cumulative Changes and Attractors in Iterated Cultural Transmissions
Jul 05, 2024



As large language models (LLMs) start interacting with each other and generating an increasing amount of text online, it becomes crucial to better understand how information is transformed as it passes from one LLM to the next. While significant research has examined individual LLM behaviors, existing studies have largely overlooked the collective behaviors and information distortions arising from iterated LLM interactions. Small biases, negligible at the single output level, risk being amplified in iterated interactions, potentially leading the content to evolve towards attractor states. In a series of telephone game experiments, we apply a transmission chain design borrowed from the human cultural evolution literature: LLM agents iteratively receive, produce, and transmit texts from the previous to the next agent in the chain. By tracking the evolution of text toxicity, positivity, difficulty, and length across transmission chains, we uncover the existence of biases and attractors, and study their dependence on the initial text, the instructions, language model, and model size. For instance, we find that more open-ended instructions lead to stronger attraction effects compared to more constrained tasks. We also find that different text properties display different sensitivity to attraction effects, with toxicity leading to stronger attractors than length. These findings highlight the importance of accounting for multi-step transmission dynamics and represent a first step towards a more comprehensive understanding of LLM cultural dynamics.
Cultural evolution in populations of Large Language Models
Mar 13, 2024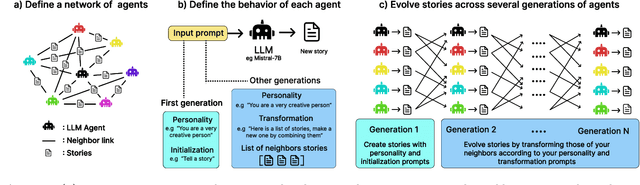
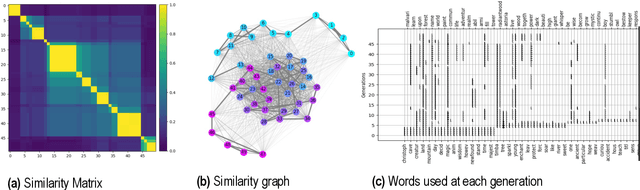
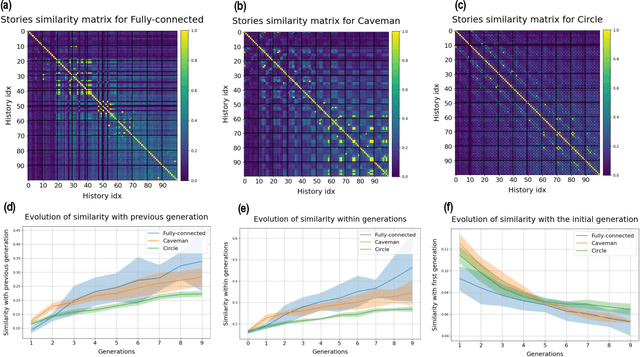

Research in cultural evolution aims at providing causal explanations for the change of culture over time. Over the past decades, this field has generated an important body of knowledge, using experimental, historical, and computational methods. While computational models have been very successful at generating testable hypotheses about the effects of several factors, such as population structure or transmission biases, some phenomena have so far been more complex to capture using agent-based and formal models. This is in particular the case for the effect of the transformations of social information induced by evolved cognitive mechanisms. We here propose that leveraging the capacity of Large Language Models (LLMs) to mimic human behavior may be fruitful to address this gap. On top of being an useful approximation of human cultural dynamics, multi-agents models featuring generative agents are also important to study for their own sake. Indeed, as artificial agents are bound to participate more and more to the evolution of culture, it is crucial to better understand the dynamics of machine-generated cultural evolution. We here present a framework for simulating cultural evolution in populations of LLMs, allowing the manipulation of variables known to be important in cultural evolution, such as network structure, personality, and the way social information is aggregated and transformed. The software we developed for conducting these simulations is open-source and features an intuitive user-interface, which we hope will help to build bridges between the fields of cultural evolution and generative artificial intelligence.
Evolving Reservoirs for Meta Reinforcement Learning
Dec 09, 2023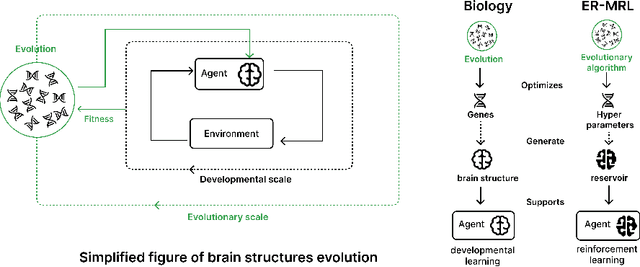
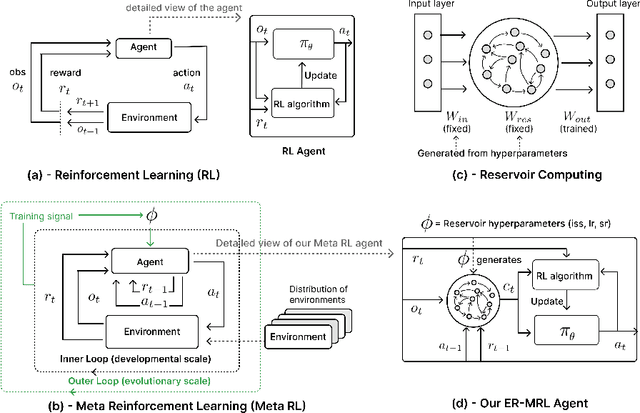
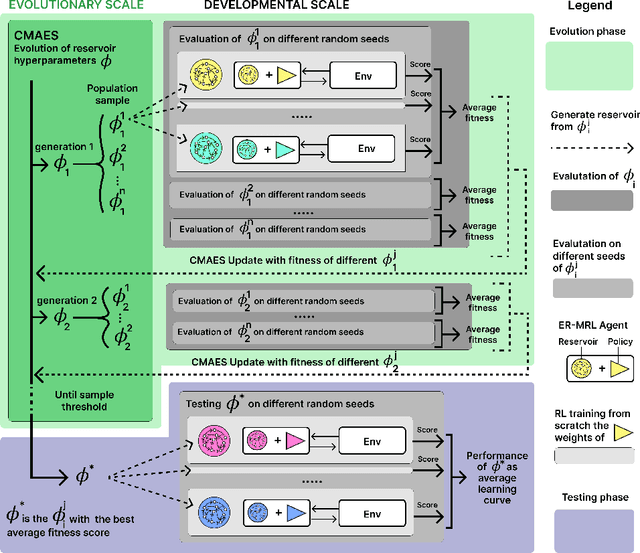
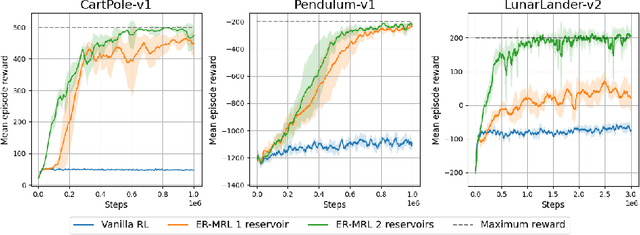
Animals often demonstrate a remarkable ability to adapt to their environments during their lifetime. They do so partly due to the evolution of morphological and neural structures. These structures capture features of environments shared between generations to bias and speed up lifetime learning. In this work, we propose a computational model for studying a mechanism that can enable such a process. We adopt a computational framework based on meta reinforcement learning as a model of the interplay between evolution and development. At the evolutionary scale, we evolve reservoirs, a family of recurrent neural networks that differ from conventional networks in that one optimizes not the weight values but hyperparameters of the architecture: the later control macro-level properties, such as memory and dynamics. At the developmental scale, we employ these evolved reservoirs to facilitate the learning of a behavioral policy through Reinforcement Learning (RL). Within an RL agent, a reservoir encodes the environment state before providing it to an action policy. We evaluate our approach on several 2D and 3D simulated environments. Our results show that the evolution of reservoirs can improve the learning of diverse challenging tasks. We study in particular three hypotheses: the use of an architecture combining reservoirs and reinforcement learning could enable (1) solving tasks with partial observability, (2) generating oscillatory dynamics that facilitate the learning of locomotion tasks, and (3) facilitating the generalization of learned behaviors to new tasks unknown during the evolution phase.