 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSDC: A Dataset of $\underline{U}$ser $\underline{S}$tance and $\underline{D}$ogmatism in Long $\underline{C}$onversations
Jun 24, 2024Identifying user's opinions and stances in long conversation threads on various topics can be extremely critical for enhanced personalization, market research, political campaigns, customer service, conflict resolution, targeted advertising, and content moderation. Hence, training language models to automate this task is critical. However, to train such models, gathering manual annotations has multiple challenges: 1) It is time-consuming and costly; 2) Conversation threads could be very long, increasing chances of noisy annotations; and 3) Interpreting instances where a user changes their opinion within a conversation is difficult because often such transitions are subtle and not expressed explicitly. Inspired by the recent success of large language models (LLMs) for complex natural language processing (NLP) tasks, we leverage Mistral Large and GPT-4 to automate the human annotation process on the following two tasks while also providing reasoning: i) User Stance classification, which involves labeling a user's stance of a post in a conversation on a five-point scale; ii) User Dogmatism classification, which deals with labeling a user's overall opinion in the conversation on a four-point scale. The majority voting on zero-shot, one-shot, and few-shot annotations from these two LLMs on 764 multi-user Reddit conversations helps us curate the USDC dataset. USDC is then used to finetune and instruction-tune multiple deployable small language models for the 5-class stance and 4-class dogmatism classification tasks. We make the code and dataset publicly available [https://anonymous.4open.science/r/USDC-0F7F].
Multi-Task Text Classification using Graph Convolutional Networks for Large-Scale Low Resource Language
May 02, 2022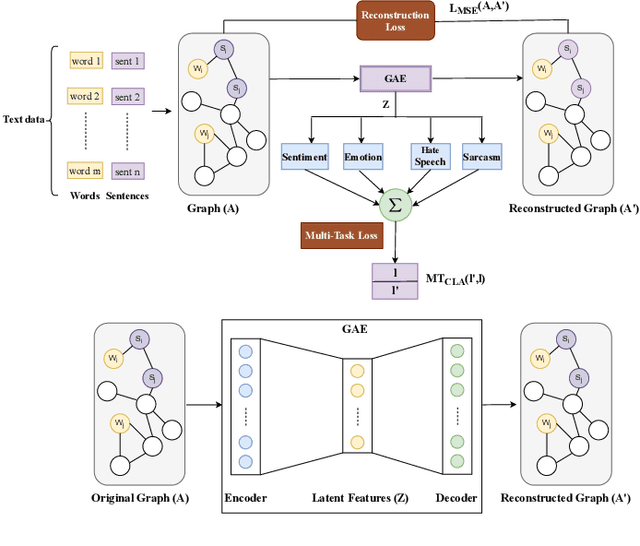
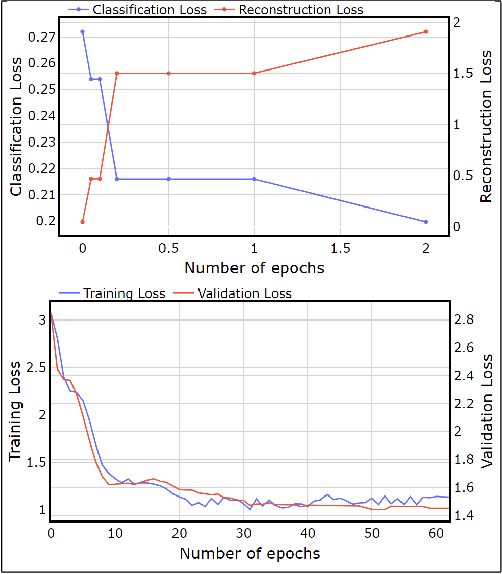

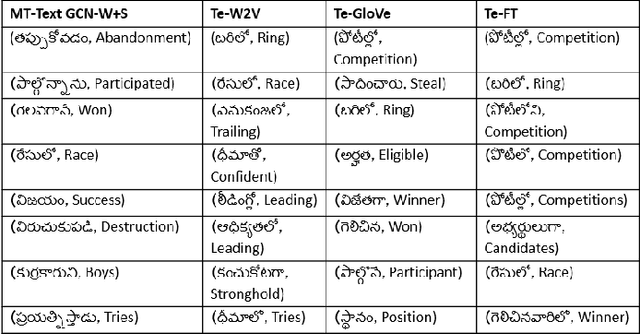
Graph Convolutional Networks (GCN) have achieved state-of-art results on single text classification tasks like sentiment analysis, emotion detection, etc. However, the performance is achieved by testing and reporting on resource-rich languages like English. Applying GCN for multi-task text classification is an unexplored area. Moreover, training a GCN or adopting an English GCN for Indian languages is often limited by data availability, rich morphological variation, syntax, and semantic differences. In this paper, we study the use of GCN for the Telugu language in single and multi-task settings for four natural language processing (NLP) tasks, viz. sentiment analysis (SA), emotion identification (EI), hate-speech (HS), and sarcasm detection (SAR). In order to evaluate the performance of GCN with one of the Indian languages, Telugu, we analyze the GCN based models with extensive experiments on four downstream tasks. In addition, we created an annotated Telugu dataset, TEL-NLP, for the four NLP tasks. Further, we propose a supervised graph reconstruction method, Multi-Task Text GCN (MT-Text GCN) on the Telugu that leverages to simultaneously (i) learn the low-dimensional word and sentence graph embeddings from word-sentence graph reconstruction using graph autoencoder (GAE) and (ii) perform multi-task text classification using these latent sentence graph embeddings. We argue that our proposed MT-Text GCN achieves significant improvements on TEL-NLP over existing Telugu pretrained word embeddings, and multilingual pretrained Transformer models: mBERT, and XLM-R. On TEL-NLP, we achieve a high F1-score for four NLP tasks: SA (0.84), EI (0.55), HS (0.83) and SAR (0.66). Finally, we show our model's quantitative and qualitative analysis on the four NLP tasks in Telugu.