 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAE-ISumm: Unsupervised Graph-Based Summarization of Indian Languages
Dec 25, 2022Document summarization aims to create a precise and coherent summary of a text document. Many deep learning summarization models are developed mainly for English, often requiring a large training corpus and efficient pre-trained language models and tools. However, English summarization models for low-resource Indian languages are often limited by rich morphological variation, syntax, and semantic differences. In this paper, we propose GAE-ISumm, an unsupervised Indic summarization model that extracts summaries from text documents. In particular, our proposed model, GAE-ISumm uses Graph Autoencoder (GAE) to learn text representations and a document summary jointly. We also provide a manually-annotated Telugu summarization dataset TELSUM, to experiment with our model GAE-ISumm. Further, we experiment with the most publicly available Indian language summarization datasets to investigate the effectiveness of GAE-ISumm on other Indian languages. Our experiments of GAE-ISumm in seven languages make the following observations: (i) it is competitive or better than state-of-the-art results on all datasets, (ii) it reports benchmark results on TELSUM, and (iii) the inclusion of positional and cluster information in the proposed model improved the performance of summaries.
Multi-Task Text Classification using Graph Convolutional Networks for Large-Scale Low Resource Language
May 02, 2022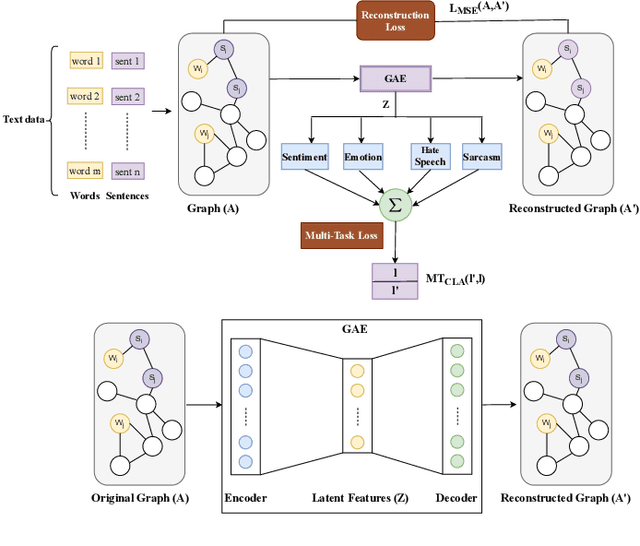

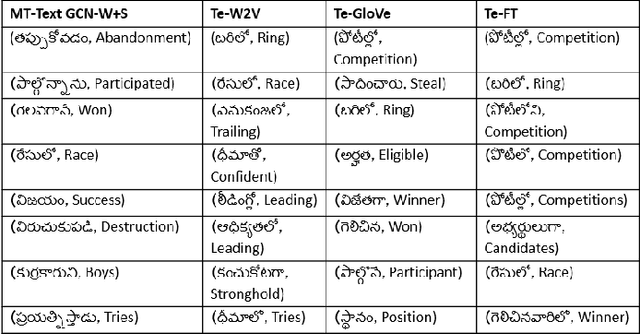
Graph Convolutional Networks (GCN) have achieved state-of-art results on single text classification tasks like sentiment analysis, emotion detection, etc. However, the performance is achieved by testing and reporting on resource-rich languages like English. Applying GCN for multi-task text classification is an unexplored area. Moreover, training a GCN or adopting an English GCN for Indian languages is often limited by data availability, rich morphological variation, syntax, and semantic differences. In this paper, we study the use of GCN for the Telugu language in single and multi-task settings for four natural language processing (NLP) tasks, viz. sentiment analysis (SA), emotion identification (EI), hate-speech (HS), and sarcasm detection (SAR). In order to evaluate the performance of GCN with one of the Indian languages, Telugu, we analyze the GCN based models with extensive experiments on four downstream tasks. In addition, we created an annotated Telugu dataset, TEL-NLP, for the four NLP tasks. Further, we propose a supervised graph reconstruction method, Multi-Task Text GCN (MT-Text GCN) on the Telugu that leverages to simultaneously (i) learn the low-dimensional word and sentence graph embeddings from word-sentence graph reconstruction using graph autoencoder (GAE) and (ii) perform multi-task text classification using these latent sentence graph embeddings. We argue that our proposed MT-Text GCN achieves significant improvements on TEL-NLP over existing Telugu pretrained word embeddings, and multilingual pretrained Transformer models: mBERT, and XLM-R. On TEL-NLP, we achieve a high F1-score for four NLP tasks: SA (0.84), EI (0.55), HS (0.83) and SAR (0.66). Finally, we show our model's quantitative and qualitative analysis on the four NLP tasks in Telugu.