 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass-Difficulty Based Methods for Long-Tailed Visual Recognition
Jul 29, 2022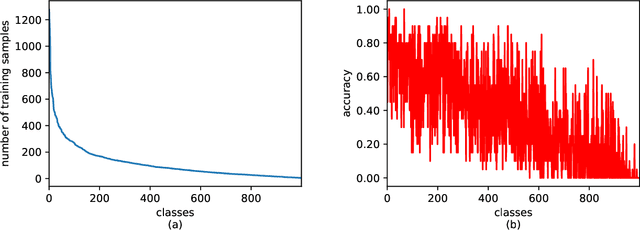
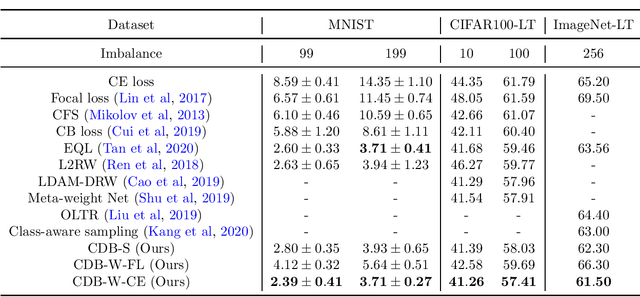
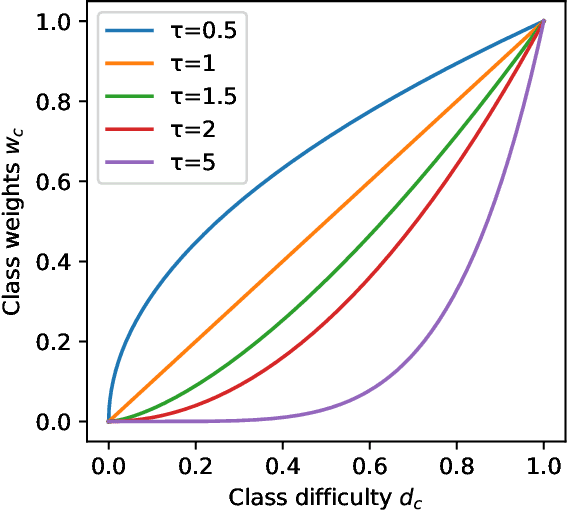

Long-tailed datasets are very frequently encountered in real-world use cases where few classes or categories (known as majority or head classes) have higher number of data samples compared to the other classes (known as minority or tail classes). Training deep neural networks on such datasets gives results biased towards the head classes. So far, researchers have come up with multiple weighted loss and data re-sampling techniques in efforts to reduce the bias. However, most of such techniques assume that the tail classes are always the most difficult classes to learn and therefore need more weightage or attention. Here, we argue that the assumption might not always hold true. Therefore, we propose a novel approach to dynamically measure the instantaneous difficulty of each class during the training phase of the model. Further, we use the difficulty measures of each class to design a novel weighted loss technique called `class-wise difficulty based weighted (CDB-W) loss' and a novel data sampling technique called `class-wise difficulty based sampling (CDB-S)'. To verify the wide-scale usability of our CDB methods, we conducted extensive experiments on multiple tasks such as image classification, object detection, instance segmentation and video-action classification. Results verified that CDB-W loss and CDB-S could achieve state-of-the-art results on many class-imbalanced datasets such as ImageNet-LT, LVIS and EGTEA, that resemble real-world use cases.
Sensor-Augmented Egocentric-Video Captioning with Dynamic Modal Attention
Sep 07, 2021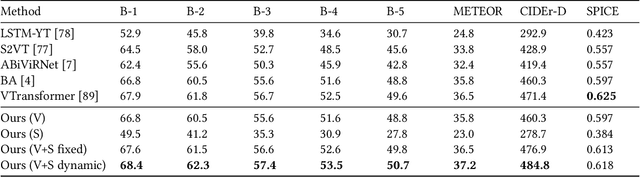


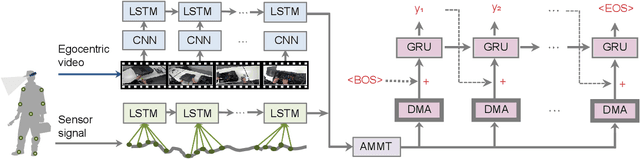
Automatically describing video, or video captioning, has been widely studied in the multimedia field. This paper proposes a new task of sensor-augmented egocentric-video captioning, a newly constructed dataset for it called MMAC Captions, and a method for the newly proposed task that effectively utilizes multi-modal data of video and motion sensors, or inertial measurement units (IMUs). While conventional video captioning tasks have difficulty in dealing with detailed descriptions of human activities due to the limited view of a fixed camera, egocentric vision has greater potential to be used for generating the finer-grained descriptions of human activities on the basis of a much closer view. In addition, we utilize wearable-sensor data as auxiliary information to mitigate the inherent problems in egocentric vision: motion blur, self-occlusion, and out-of-camera-range activities. We propose a method for effectively utilizing the sensor data in combination with the video data on the basis of an attention mechanism that dynamically determines the modality that requires more attention, taking the contextual information into account. We compared the proposed sensor-fusion method with strong baselines on the MMAC Captions dataset and found that using sensor data as supplementary information to the egocentric-video data was beneficial, and that our proposed method outperformed the strong baselines, demonstrating the effectiveness of the proposed method.
Class-Wise Difficulty-Balanced Loss for Solving Class-Imbalance
Oct 05, 2020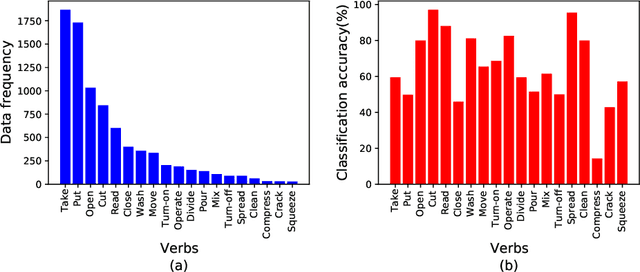
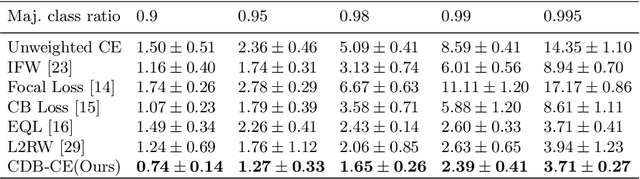
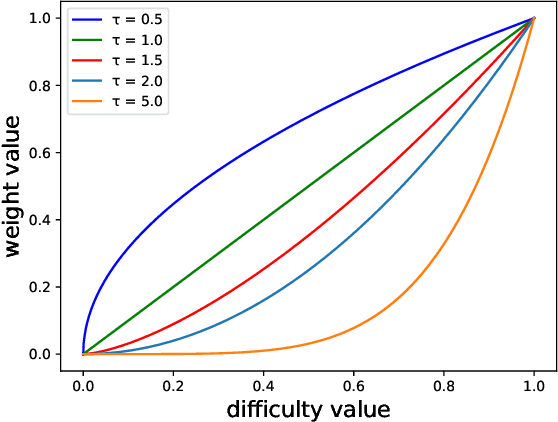
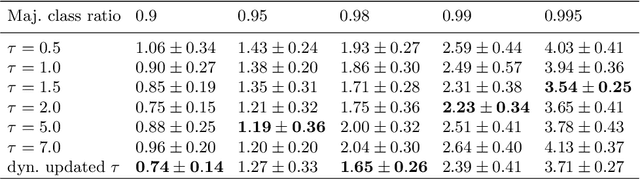
Class-imbalance is one of the major challenges in real world datasets, where a few classes (called majority classes) constitute much more data samples than the rest (called minority classes). Learning deep neural networks using such datasets leads to performances that are typically biased towards the majority classes. Most of the prior works try to solve class-imbalance by assigning more weights to the minority classes in various manners (e.g., data re-sampling, cost-sensitive learning). However, we argue that the number of available training data may not be always a good clue to determine the weighting strategy because some of the minority classes might be sufficiently represented even by a small number of training data. Overweighting samples of such classes can lead to drop in the model's overall performance. We claim that the 'difficulty' of a class as perceived by the model is more important to determine the weighting. In this light, we propose a novel loss function named Class-wise Difficulty-Balanced loss, or CDB loss, which dynamically distributes weights to each sample according to the difficulty of the class that the sample belongs to. Note that the assigned weights dynamically change as the 'difficulty' for the model may change with the learning progress. Extensive experiments are conducted on both image (artificially induced class-imbalanced MNIST, long-tailed CIFAR and ImageNet-LT) and video (EGTEA) datasets. The results show that CDB loss consistently outperforms the recently proposed loss functions on class-imbalanced datasets irrespective of the data type (i.e., video or image).
Attributes' Importance for Zero-Shot Pose-Classification Based on Wearable Sensors
Aug 02, 2018
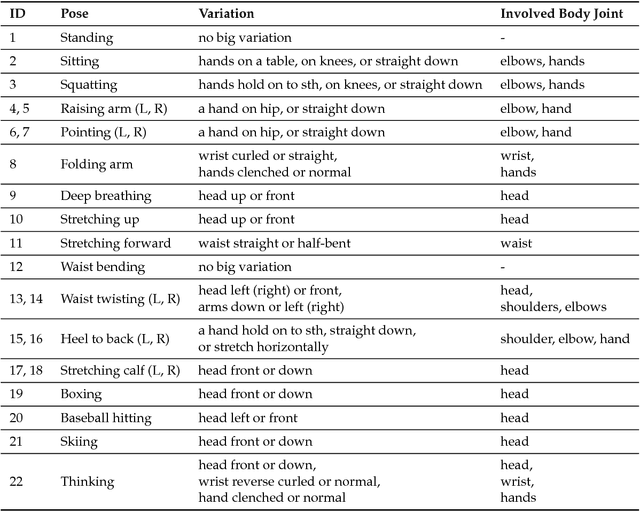

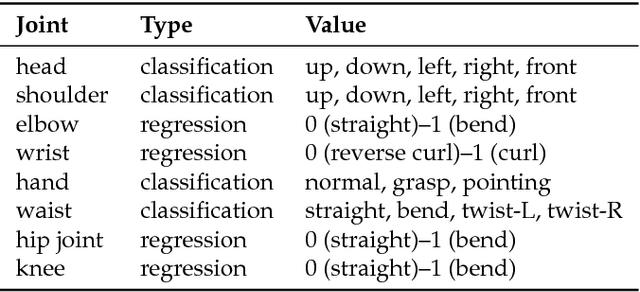
This paper presents a simple yet effective method for improving the performance of zero-shot learning (ZSL). ZSL classifies instances of unseen classes, from which no training data is available, by utilizing the attributes of the classes. Conventional ZSL methods have equally dealt with all the available attributes, but this sometimes causes misclassification. This is because an attribute that is effective for classifying instances of one class is not always effective for another class. In this case, a metric of classifying the latter class can be undesirably influenced by the irrelevant attribute. This paper solves this problem by taking the importance of each attribute for each class into account when calculating the metric. In addition to the proposal of this new method, this paper also contributes by providing a dataset for pose classification based on wearable sensors, named HDPoseDS. It contains 22 classes of poses performed by 10 subjects with 31 IMU sensors across full body. To the best of our knowledge, it is the richest wearable-sensor dataset especially in terms of sensor density, and thus it is suitable for studying zero-shot pose/action recognition. The presented method was evaluated on HDPoseDS and outperformed relative improvement of 5.9% in comparison to the best baseline method.
* The paper was published at Sensors, an open access journal (http://www.mdpi.com/1424-8220/18/8/2485). This article belongs to the Special Issue Artificial Intelligence and Machine Learning in Sensors Networks