 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompter: Utilizing Large Language Model Prompting for a Data Efficient Embodied Instruction Following
Nov 07, 2022Embodied Instruction Following (EIF) studies how mobile manipulator robots should be controlled to accomplish long-horizon tasks specified by natural language instructions. While most research on EIF are conducted in simulators, the ultimate goal of the field is to deploy the agents in real life. As such, it is important to minimize the data cost required for training an agent, to help the transition from sim to real. However, many studies only focus on the performance and overlook the data cost -- modules that require separate training on extra data are often introduced without a consideration on deployability. In this work, we propose FILM++ which extends the existing work FILM with modifications that do not require extra data. While all data-driven modules are kept constant, FILM++ more than doubles FILM's performance. Furthermore, we propose Prompter, which replaces FILM++'s semantic search module with language model prompting. Unlike FILM++'s implementation that requires training on extra sets of data, no training is needed for our prompting based implementation while achieving better or at least comparable performance. Prompter achieves 42.64% and 45.72% on the ALFRED benchmark with high-level instructions only and with step-by-step instructions, respectively, outperforming the previous state of the art by 6.57% and 10.31%.
Weakly-Supervised Crack Detection
Jun 14, 2022



Pixel-level crack segmentation is widely studied due to its high impact on building and road inspections. Recent studies have made significant improvements in accuracy, but overlooked the annotation cost bottleneck. To resolve this issue, we reformulate the crack segmentation problem as a weakly-supervised problem, and propose a two-branched inference framework and an annotation refinement module that requires no additional data, in order to counteract the loss in annotation quality. Experimental results confirm the effectiveness of the proposed method in crack segmentation as well as other target domains.
Crack Detection as a Weakly-Supervised Problem: Towards Achieving Less Annotation-Intensive Crack Detectors
Nov 04, 2020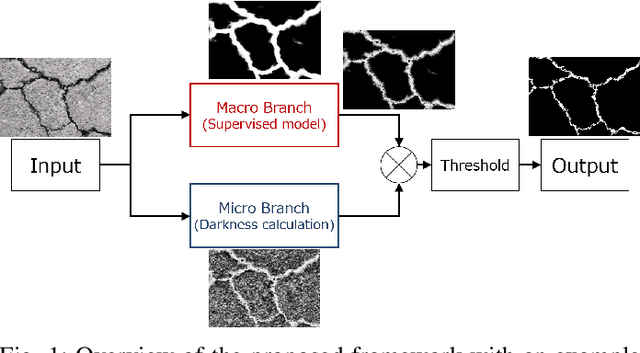



Automatic crack detection is a critical task that has the potential to drastically reduce labor-intensive building and road inspections currently being done manually. Recent studies in this field have significantly improved the detection accuracy. However, the methods often heavily rely on costly annotation processes. In addition, to handle a wide variety of target domains, new batches of annotations are usually required for each new environment. This makes the data annotation cost a significant bottleneck when deploying crack detection systems in real life. To resolve this issue, we formulate the crack detection problem as a weakly-supervised problem and propose a two-branched framework. By combining predictions of a supervised model trained on low quality annotations with predictions based on pixel brightness, our framework is less affected by the annotation quality. Experimental results show that the proposed framework retains high detection accuracy even when provided with low quality annotations. Implementation of the proposed framework is publicly available at https://github.com/hitachi-rd-cv/weakly-sup-crackdet.