 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplit and Connect: A Universal Tracklet Booster for Multi-Object Tracking
Paper and Code
May 06, 2021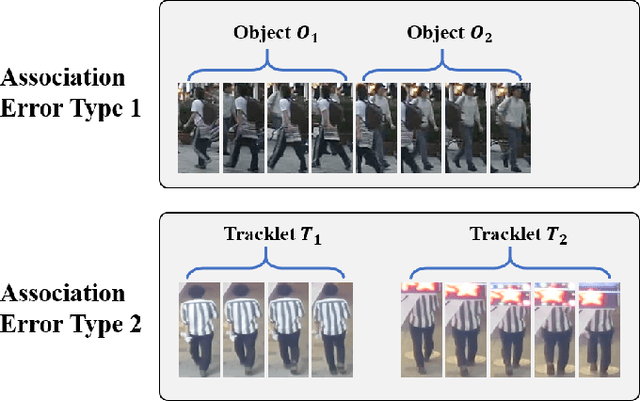
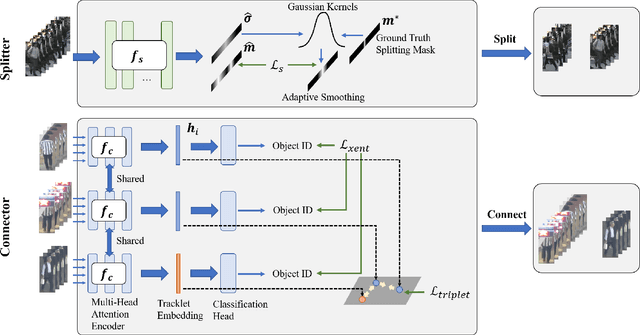

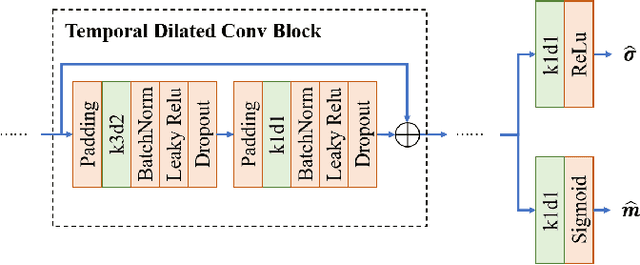
Multi-object tracking (MOT) is an essential task in the computer vision field. With the fast development of deep learning technology in recent years, MOT has achieved great improvement. However, some challenges still remain, such as sensitiveness to occlusion, instability under different lighting conditions, non-robustness to deformable objects, etc. To address such common challenges in most of the existing trackers, in this paper, a tracklet booster algorithm is proposed, which can be built upon any other tracker. The motivation is simple and straightforward: split tracklets on potential ID-switch positions and then connect multiple tracklets into one if they are from the same object. In other words, the tracklet booster consists of two parts, i.e., Splitter and Connector. First, an architecture with stacked temporal dilated convolution blocks is employed for the splitting position prediction via label smoothing strategy with adaptive Gaussian kernels. Then, a multi-head self-attention based encoder is exploited for the tracklet embedding, which is further used to connect tracklets into larger groups. We conduct sufficient experiments on MOT17 and MOT20 benchmark datasets, which demonstrates promising results. Combined with the proposed tracklet booster, existing trackers usually can achieve large improvements on the IDF1 score, which shows the effectiveness of the proposed method.