 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLength-Controllable Image Captioning
Paper and Code
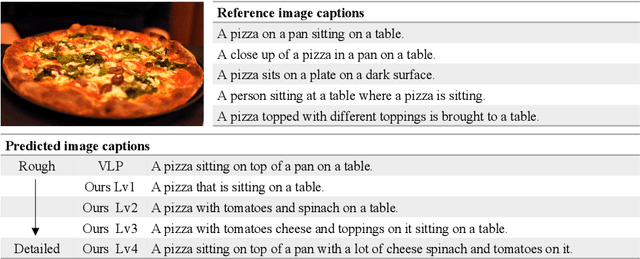



The last decade has witnessed remarkable progress in the image captioning task; however, most existing methods cannot control their captions, \emph{e.g.}, choosing to describe the image either roughly or in detail. In this paper, we propose to use a simple length level embedding to endow them with this ability. Moreover, due to their autoregressive nature, the computational complexity of existing models increases linearly as the length of the generated captions grows. Thus, we further devise a non-autoregressive image captioning approach that can generate captions in a length-irrelevant complexity. We verify the merit of the proposed length level embedding on three models: two state-of-the-art (SOTA) autoregressive models with different types of decoder, as well as our proposed non-autoregressive model, to show its generalization ability. In the experiments, our length-controllable image captioning models not only achieve SOTA performance on the challenging MS COCO dataset but also generate length-controllable and diverse image captions. Specifically, our non-autoregressive model outperforms the autoregressive baselines in terms of controllability and diversity, and also significantly improves the decoding efficiency for long captions. Our code and models are released at \textcolor{magenta}{\texttt{https://github.com/bearcatt/LaBERT}}.