 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmoothie: Label Free Language Model Routing
Dec 06, 2024



Large language models (LLMs) are increasingly used in applications where LLM inputs may span many different tasks. Recent work has found that the choice of LLM is consequential, and different LLMs may be good for different input samples. Prior approaches have thus explored how engineers might select an LLM to use for each sample (i.e. routing). While existing routing methods mostly require training auxiliary models on human-annotated data, our work explores whether it is possible to perform unsupervised routing. We propose Smoothie, a weak supervision-inspired routing approach that requires no labeled data. Given a set of outputs from different LLMs, Smoothie constructs a latent variable graphical model over embedding representations of observable LLM outputs and unknown "true" outputs. Using this graphical model, we estimate sample-dependent quality scores for each LLM, and route each sample to the LLM with the highest corresponding score. We find that Smoothie's LLM quality-scores correlate with ground-truth model quality (correctly identifying the optimal model on 9/14 tasks), and that Smoothie outperforms baselines for routing by up to 10 points accuracy.
Incidental Polysemanticity
Dec 05, 2023



Polysemantic neurons (neurons that activate for a set of unrelated features) have been seen as a significant obstacle towards interpretability of task-optimized deep networks, with implications for AI safety. The classic origin story of polysemanticity is that the data contains more "features" than neurons, such that learning to perform a task forces the network to co-allocate multiple unrelated features to the same neuron, endangering our ability to understand the network's internal processing. In this work, we present a second and non-mutually exclusive origin story of polysemanticity. We show that polysemanticity can arise incidentally, even when there are ample neurons to represent all features in the data, using a combination of theory and experiments. This second type of polysemanticity occurs because random initialization can, by chance alone, initially assign multiple features to the same neuron, and the training dynamics then strengthen such overlap. Due to its origin, we term this \textit{incidental polysemanticity}.
Stanford MLab at SemEval-2023 Task 10: Exploring GloVe- and Transformer-Based Methods for the Explainable Detection of Online Sexism
May 07, 2023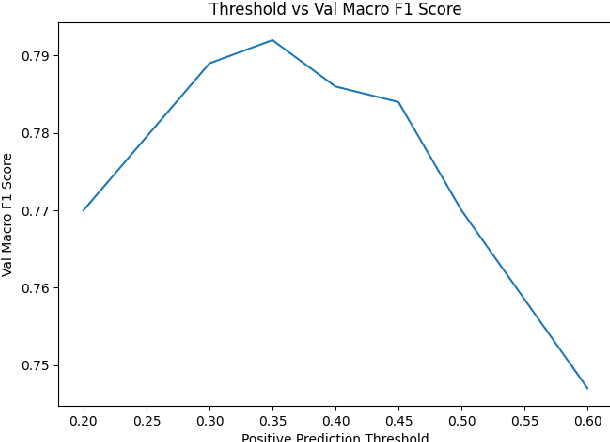



In this paper, we discuss the methods we applied at SemEval-2023 Task 10: Towards the Explainable Detection of Online Sexism. Given an input text, we perform three classification tasks to predict whether the text is sexist and classify the sexist text into subcategories in order to provide an additional explanation as to why the text is sexist. We explored many different types of models, including GloVe embeddings as the baseline approach, transformer-based deep learning models like BERT, RoBERTa, and DeBERTa, ensemble models, and model blending. We explored various data cleaning and augmentation methods to improve model performance. Pre-training transformer models yielded significant improvements in performance, and ensembles and blending slightly improved robustness in the F1 score.