 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMC$^2$: Monte Carlo Correction for Fast Elliptic PDE Solving
May 10, 2026Partial differential equation (PDE) solvers underpin scientific computing, but real-world deployment is bounded by compute. Classical Monte Carlo solvers such as Walk-on-Spheres (WoS) are unbiased and geometry-agnostic but are slow. Learned solvers are fast but biased and brittle under distribution shift. We present \textbf{MC$^2$}, a hybrid WoS-Neural Network (WoS-NN) PDE solver that treats a low-budget Monte Carlo solution as a structured estimator of the true field and learns a single-pass neural correction to recover a high-fidelity solution. MC$^2$ matches the accuracy of solutions using over $1000\times$ more Monte Carlo compute, outperforming all evaluated classical, denoising, and neural-operator baselines. To enable reproducible study of finite-compute PDE solving, we additionally release \textbf{PDEZoo}, the largest standardized elliptic PDE benchmark to date: 2M PDEs spanning five elliptic families and unlimited geometric compositions, with analytic ground truth and multi-budget Monte Carlo trajectories. Together \textbf{MC$^2$} and \textbf{PDEZoo} (1) empirically establish that finite-sample Monte Carlo error is structured, learnable, and correctable in a single forward pass, (2) show that we can solve PDEs $\sim$\textbf{1000x} faster than with just WoS, and (3) provide the evaluation infrastructure the field has so far lacked.
What Should Baby Models Read? Exploring Sample-Efficient Data Composition on Model Performance
Nov 11, 2024
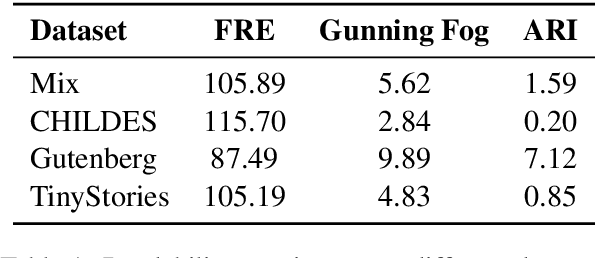

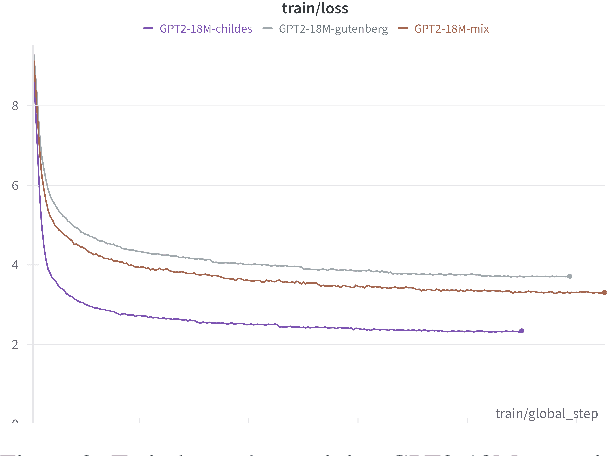
We explore the impact of pre-training data composition on the performance of small language models in a sample-efficient setting. Using datasets limited to 10 million words, we evaluate several dataset sources, including child-directed speech (CHILDES), classic books (Gutenberg), synthetic data (TinyStories), and a mix of these (Mix) across different model sizes ranging from 18 million to 705 million parameters. Our experiments show that smaller models (e.g., GPT2-97M, GPT2-705M, Llama-360M) perform better when trained on more complex and rich datasets like Gutenberg. Models trained on the CHILDES and TinyStories datasets underperformed across all model sizes. These findings suggest that the optimal dataset for sample efficient training depends on the model size, and that neither child-directed speech nor simplified stories are optimal for language models of all sizes. We highlight the importance of considering both dataset composition and model capacity for effective sample efficient language model training.
Stanford MLab at SemEval-2023 Task 10: Exploring GloVe- and Transformer-Based Methods for the Explainable Detection of Online Sexism
May 07, 2023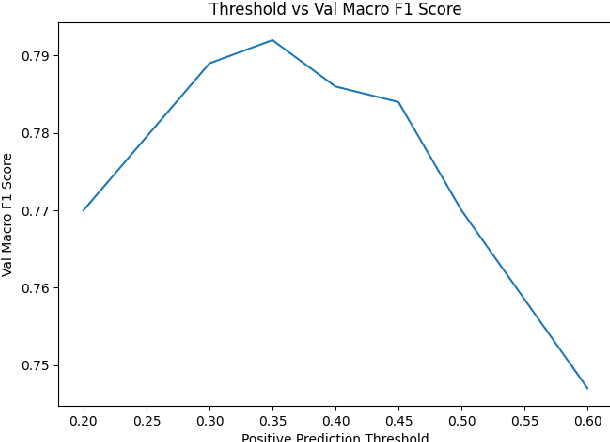



In this paper, we discuss the methods we applied at SemEval-2023 Task 10: Towards the Explainable Detection of Online Sexism. Given an input text, we perform three classification tasks to predict whether the text is sexist and classify the sexist text into subcategories in order to provide an additional explanation as to why the text is sexist. We explored many different types of models, including GloVe embeddings as the baseline approach, transformer-based deep learning models like BERT, RoBERTa, and DeBERTa, ensemble models, and model blending. We explored various data cleaning and augmentation methods to improve model performance. Pre-training transformer models yielded significant improvements in performance, and ensembles and blending slightly improved robustness in the F1 score.