 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStanford MLab at SemEval-2023 Task 10: Exploring GloVe- and Transformer-Based Methods for the Explainable Detection of Online Sexism
Paper and Code
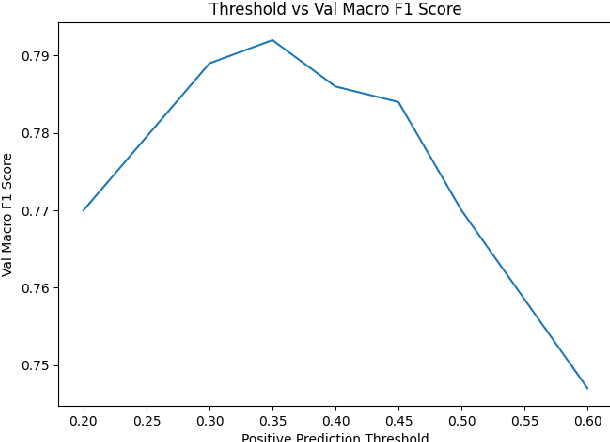



In this paper, we discuss the methods we applied at SemEval-2023 Task 10: Towards the Explainable Detection of Online Sexism. Given an input text, we perform three classification tasks to predict whether the text is sexist and classify the sexist text into subcategories in order to provide an additional explanation as to why the text is sexist. We explored many different types of models, including GloVe embeddings as the baseline approach, transformer-based deep learning models like BERT, RoBERTa, and DeBERTa, ensemble models, and model blending. We explored various data cleaning and augmentation methods to improve model performance. Pre-training transformer models yielded significant improvements in performance, and ensembles and blending slightly improved robustness in the F1 score.