 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgecViL: Cross-Lingual Training of Vision-Language Models using Knowledge Distillation
Jun 09, 2022
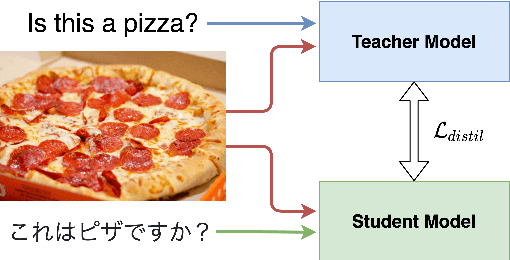

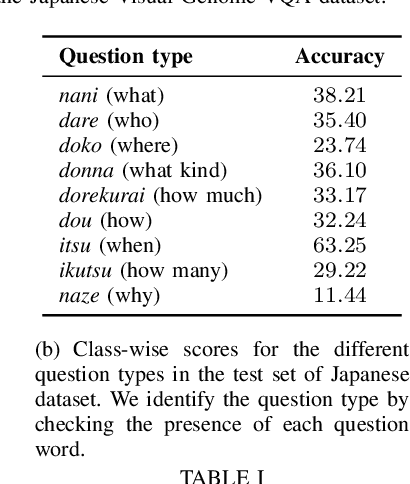
Vision-and-language tasks are gaining popularity in the research community, but the focus is still mainly on English. We propose a pipeline that utilizes English-only vision-language models to train a monolingual model for a target language. We propose to extend OSCAR+, a model which leverages object tags as anchor points for learning image-text alignments, to train on visual question answering datasets in different languages. We propose a novel approach to knowledge distillation to train the model in other languages using parallel sentences. Compared to other models that use the target language in the pretraining corpora, we can leverage an existing English model to transfer the knowledge to the target language using significantly lesser resources. We also release a large-scale visual question answering dataset in Japanese and Hindi language. Though we restrict our work to visual question answering, our model can be extended to any sequence-level classification task, and it can be extended to other languages as well. This paper focuses on two languages for the visual question answering task - Japanese and Hindi. Our pipeline outperforms the current state-of-the-art models by a relative increase of 4.4% and 13.4% respectively in accuracy.
Volta at SemEval-2021 Task 9: Statement Verification and Evidence Finding with Tables using TAPAS and Transfer Learning
Jun 17, 2021

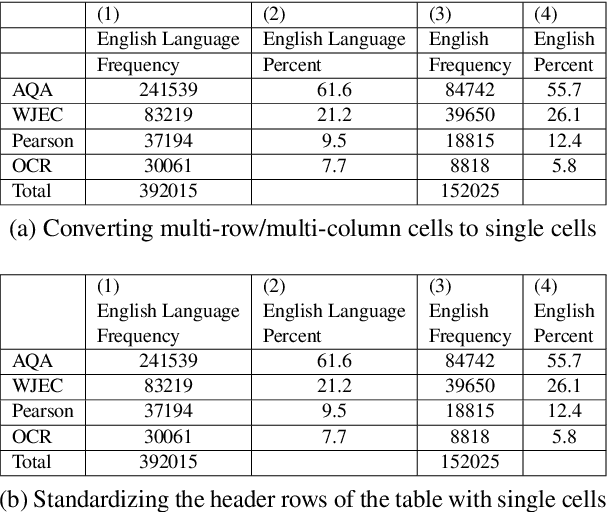

Tables are widely used in various kinds of documents to present information concisely. Understanding tables is a challenging problem that requires an understanding of language and table structure, along with numerical and logical reasoning. In this paper, we present our systems to solve Task 9 of SemEval-2021: Statement Verification and Evidence Finding with Tables (SEM-TAB-FACTS). The task consists of two subtasks: (A) Given a table and a statement, predicting whether the table supports the statement and (B) Predicting which cells in the table provide evidence for/against the statement. We fine-tune TAPAS (a model which extends BERT's architecture to capture tabular structure) for both the subtasks as it has shown state-of-the-art performance in various table understanding tasks. In subtask A, we evaluate how transfer learning and standardizing tables to have a single header row improves TAPAS' performance. In subtask B, we evaluate how different fine-tuning strategies can improve TAPAS' performance. Our systems achieve an F1 score of 67.34 in subtask A three-way classification, 72.89 in subtask A two-way classification, and 62.95 in subtask B.
ViTA: Visual-Linguistic Translation by Aligning Object Tags
Jun 08, 2021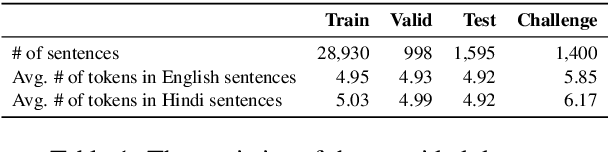
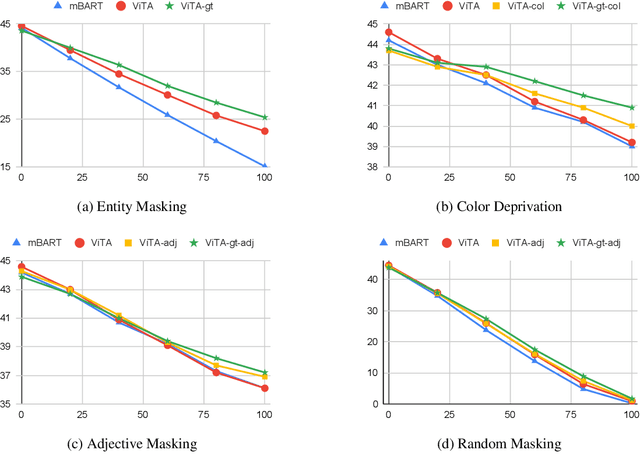
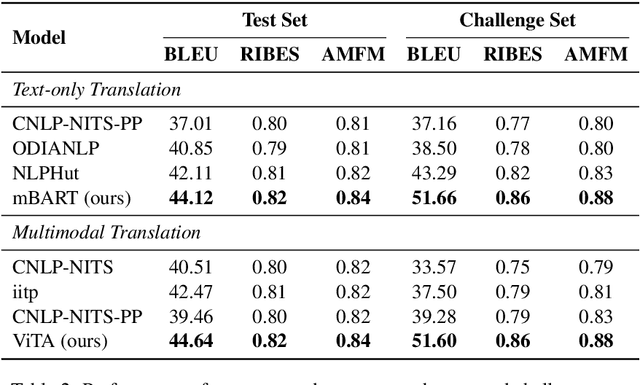

Multimodal Machine Translation (MMT) enriches the source text with visual information for translation. It has gained popularity in recent years, and several pipelines have been proposed in the same direction. Yet, the task lacks quality datasets to illustrate the contribution of visual modality in the translation systems. In this paper, we propose our system under the team name Volta for the Multimodal Translation Task of WAT 2021 from English to Hindi. We also participate in the textual-only subtask of the same language pair for which we use mBART, a pretrained multilingual sequence-to-sequence model. For multimodal translation, we propose to enhance the textual input by bringing the visual information to a textual domain by extracting object tags from the image. We also explore the robustness of our system by systematically degrading the source text. Finally, we achieve a BLEU score of 44.6 and 51.6 on the test set and challenge set of the multimodal task.
Volta at SemEval-2021 Task 6: Towards Detecting Persuasive Texts and Images using Textual and Multimodal Ensemble
Jun 01, 2021


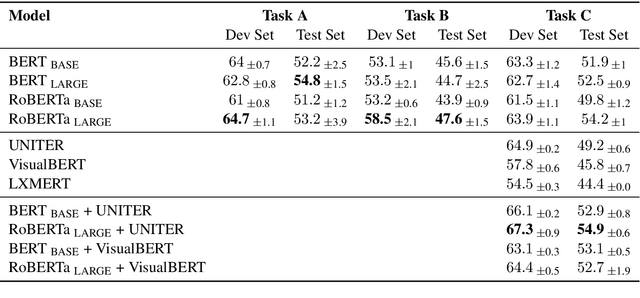
Memes are one of the most popular types of content used to spread information online. They can influence a large number of people through rhetorical and psychological techniques. The task, Detection of Persuasion Techniques in Texts and Images, is to detect these persuasive techniques in memes. It consists of three subtasks: (A) Multi-label classification using textual content, (B) Multi-label classification and span identification using textual content, and (C) Multi-label classification using visual and textual content. In this paper, we propose a transfer learning approach to fine-tune BERT-based models in different modalities. We also explore the effectiveness of ensembles of models trained in different modalities. We achieve an F1-score of 57.0, 48.2, and 52.1 in the corresponding subtasks.