 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgecViL: Cross-Lingual Training of Vision-Language Models using Knowledge Distillation
Paper and Code

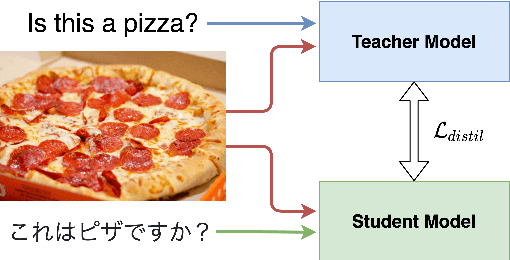

Vision-and-language tasks are gaining popularity in the research community, but the focus is still mainly on English. We propose a pipeline that utilizes English-only vision-language models to train a monolingual model for a target language. We propose to extend OSCAR+, a model which leverages object tags as anchor points for learning image-text alignments, to train on visual question answering datasets in different languages. We propose a novel approach to knowledge distillation to train the model in other languages using parallel sentences. Compared to other models that use the target language in the pretraining corpora, we can leverage an existing English model to transfer the knowledge to the target language using significantly lesser resources. We also release a large-scale visual question answering dataset in Japanese and Hindi language. Though we restrict our work to visual question answering, our model can be extended to any sequence-level classification task, and it can be extended to other languages as well. This paper focuses on two languages for the visual question answering task - Japanese and Hindi. Our pipeline outperforms the current state-of-the-art models by a relative increase of 4.4% and 13.4% respectively in accuracy.