 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascaded Information Disclosure for Generalized Evaluation of Problem Solving Capabilities
Jul 31, 2025While question-answering~(QA) benchmark performance is an automatic and scalable method to compare LLMs, it is an indirect method of evaluating their underlying problem-solving capabilities. Therefore, we propose a holistic and generalizable framework based on \emph{cascaded question disclosure} that provides a more accurate estimate of the models' problem-solving capabilities while maintaining the scalability and automation. This approach collects model responses in a stagewise manner with each stage revealing partial information about the question designed to elicit generalized reasoning in LLMs. We find that our approach not only provides a better comparison between LLMs, but also induces better intermediate traces in models compared to the standard QA paradigm. We empirically verify this behavior on diverse reasoning and knowledge-heavy QA datasets by comparing LLMs of varying sizes and families. Our approach narrows the performance gap observed in the standard QA evaluation settings, indicating that the prevalent indirect QA paradigm of evaluation overestimates the differences in performance between models. We further validate our findings by extensive ablation studies.
Towards a Unified Multimodal Reasoning Framework
Dec 22, 2023Recent advancements in deep learning have led to the development of powerful language models (LMs) that excel in various tasks. Despite these achievements, there is still room for improvement, particularly in enhancing reasoning abilities and incorporating multimodal data. This report investigates the potential impact of combining Chain-of-Thought (CoT) reasoning and Visual Question Answering (VQA) techniques to improve LM's accuracy in solving multiple-choice questions. By employing TextVQA and ScienceQA datasets, we assessed the effectiveness of three text embedding methods and three visual embedding approaches. Our experiments aimed to fill the gap in current research by investigating the combined impact of CoT and VQA, contributing to the understanding of how these techniques can improve the reasoning capabilities of state-of-the-art models like GPT-4. Results from our experiments demonstrated the potential of these approaches in enhancing LM's reasoning and question-answering capabilities, providing insights for further research and development in the field, and paving the way for more accurate and reliable AI systems that can handle complex reasoning tasks across multiple modalities.
ARB: Advanced Reasoning Benchmark for Large Language Models
Jul 28, 2023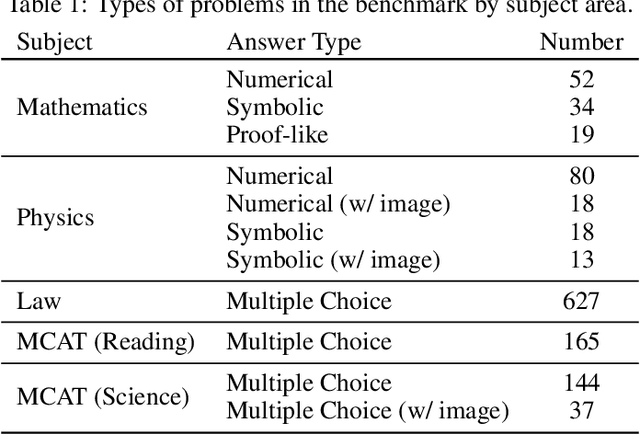
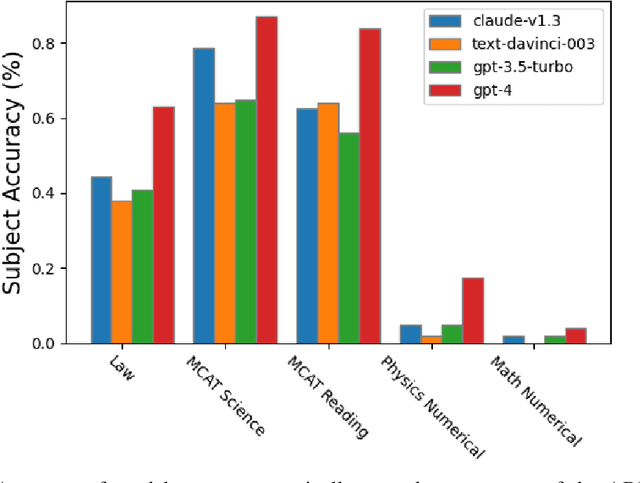


Large Language Models (LLMs) have demonstrated remarkable performance on various quantitative reasoning and knowledge benchmarks. However, many of these benchmarks are losing utility as LLMs get increasingly high scores, despite not yet reaching expert performance in these domains. We introduce ARB, a novel benchmark composed of advanced reasoning problems in multiple fields. ARB presents a more challenging test than prior benchmarks, featuring problems in mathematics, physics, biology, chemistry, and law. As a subset of ARB, we introduce a challenging set of math and physics problems which require advanced symbolic reasoning and domain knowledge. We evaluate recent models such as GPT-4 and Claude on ARB and demonstrate that current models score well below 50% on more demanding tasks. In order to improve both automatic and assisted evaluation capabilities, we introduce a rubric-based evaluation approach, allowing GPT-4 to score its own intermediate reasoning steps. Further, we conduct a human evaluation of the symbolic subset of ARB, finding promising agreement between annotators and GPT-4 rubric evaluation scores.