 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtractive Summary as Discrete Latent Variables
Paper and Code
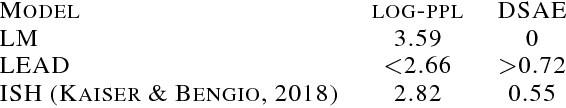
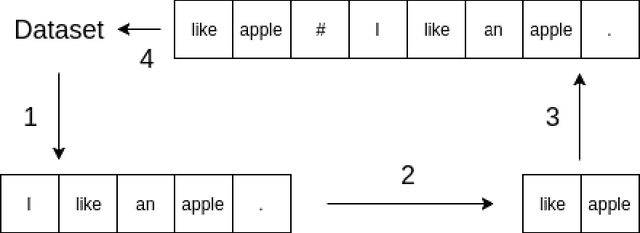


In this paper, we compare various methods to compress a text using a neural model. We found that extracting words as latent variables significantly outperforms the state-of-the-art discrete latent variable models such as VQ-VAE. Furthermore, we compare various extractive compression schemes. There are two best-performing methods that perform equally. One method is to simply choose the tokens with the highest tf-idf scores. Another is to train a bidirectional language model similar to ELMo and choose the tokens with the highest loss. If we consider any subsequence of text to be a text in a broader sense, we conclude that language is a strong compression code of itself. Our finding justifies the high quality of generation achieved with hierarchical method as in \citep{hier}, as their latent variables are nothing but natural language summary of the story. We also conclude that there is a hierarchy in language such that an entire text can be predicted much more easily based on a sequence of a small number of keywords, which can be easily found by classical methods as tf-idf. Therefore, we believe that this extraction process is crucial for generating discrete latent variables of text and, in particular, unsupervised hierarchical generation.