 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Epoch Is All You Need
Paper and Code
Jun 16, 2019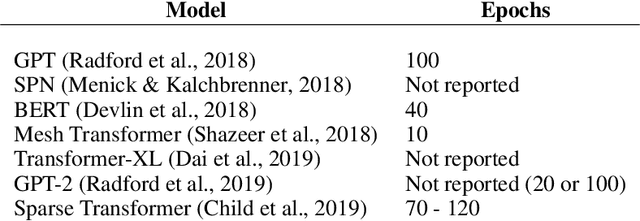



In unsupervised learning, collecting more data is not always a costly process unlike the training. For example, it is not hard to enlarge the 40GB WebText used for training GPT-2 by modifying its sampling methodology considering how many webpages there are in the Internet. On the other hand, given that training on this dataset already costs tens of thousands of dollars, training on a larger dataset naively is not cost-wise feasible. In this paper, we suggest to train on a larger dataset for only one epoch unlike the current practice, in which the unsupervised models are trained for from tens to hundreds of epochs. Furthermore, we suggest to adjust the model size and the number of iterations to be performed appropriately. We show that the performance of Transformer language model becomes dramatically improved in this way, especially if the original number of epochs is greater. For example, by replacing the training for 10 epochs with the one epoch training, this translates to 1.9-3.3x speedup in wall-clock time in our settings and more if the original number of epochs is greater. Under one epoch training, no overfitting occurs, and regularization method does nothing but slows down the training. Also, the curve of test loss over iterations follows power-law extensively. We compare the wall-clock time of the training of models with different parameter budget under one epoch training, and we show that size/iteration adjustment based on our proposed heuristics leads to 1-2.7x speedup in our cases. With the two methods combined, we achieve 3.3-5.1x speedup. Finally, we speculate various implications of one epoch training and size/iteration adjustment. In particular, based on our analysis we believe that we can reduce the cost to train the state-of-the-art models as BERT and GPT-2 dramatically, maybe even by the factor of 10.