 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffect of large-scale pre-training on full and few-shot transfer learning for natural and medical images
Paper and Code

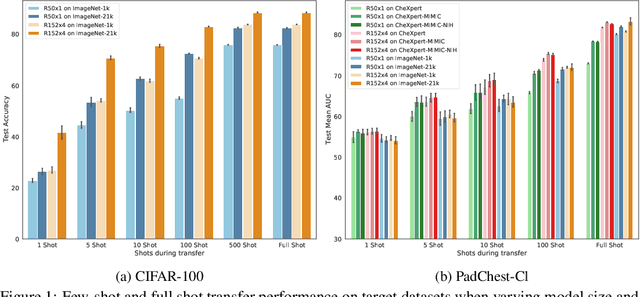

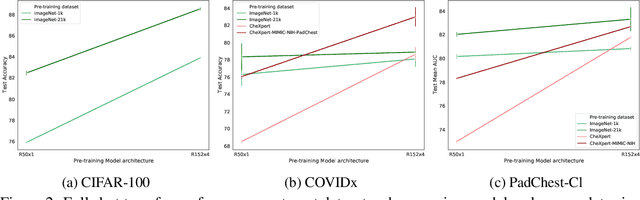
Transfer learning aims to exploit pre-trained models for more efficient follow-up training on wide range of downstream tasks and datasets, enabling successful training also on small data. Recent line of work posits strong benefits for model generalization and transfer when model size, data size, and compute budget are increased for the pre-training. It remains however still largely unclear whether the observed transfer improvement due to increase in scale also holds when source and target data distributions are far apart from each other. In this work we conduct large-scale pre-training on large source datasets of either natural (ImageNet-21k/1k) or medical chest X-Ray images and compare full and few-shot transfer using different target datasets from both natural and medical imaging domains. Our observations provide evidence that while pre-training and transfer on closely related datasets do show clear benefit of increasing model and data size during pre-training, such benefits are not clearly visible when source and target datasets are further apart. These observations hold across both full and few-shot transfer and indicate that scaling laws pointing to improvement of generalization and transfer with increasing model and data size are incomplete and should be revised by taking into account the type and proximity of the source and target data, to correctly predict the effect of model and data scale during pre-training on transfer. Remarkably, in full shot transfer to a large X-Ray chest imaging target (PadChest), the largest model pre-trained on ImageNet-21k slightly outperforms best models pre-trained on large X-Ray chest imaging data. This indicates possibility to obtain high quality models for domain-specific transfer even without access to large domain-specific data, by pre-training instead on comparably very large, generic source data.