 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretrained Encoders are All You Need
Jun 09, 2021



Data-efficiency and generalization are key challenges in deep learning and deep reinforcement learning as many models are trained on large-scale, domain-specific, and expensive-to-label datasets. Self-supervised models trained on large-scale uncurated datasets have shown successful transfer to diverse settings. We investigate using pretrained image representations and spatio-temporal attention for state representation learning in Atari. We also explore fine-tuning pretrained representations with self-supervised techniques, i.e., contrastive predictive coding, spatio-temporal contrastive learning, and augmentations. Our results show that pretrained representations are at par with state-of-the-art self-supervised methods trained on domain-specific data. Pretrained representations, thus, yield data and compute-efficient state representations. https://github.com/PAL-ML/PEARL_v1
Personalizing Pre-trained Models
Jun 02, 2021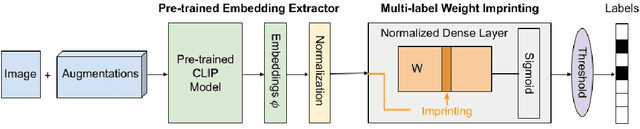
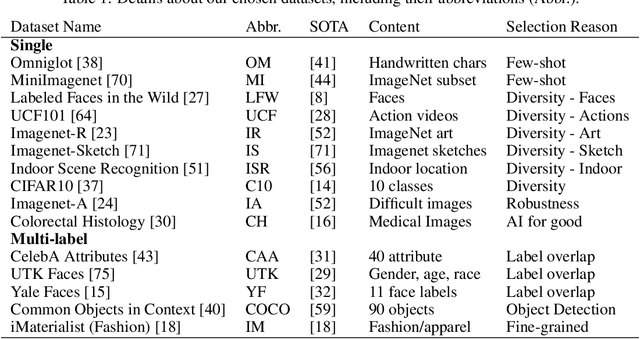
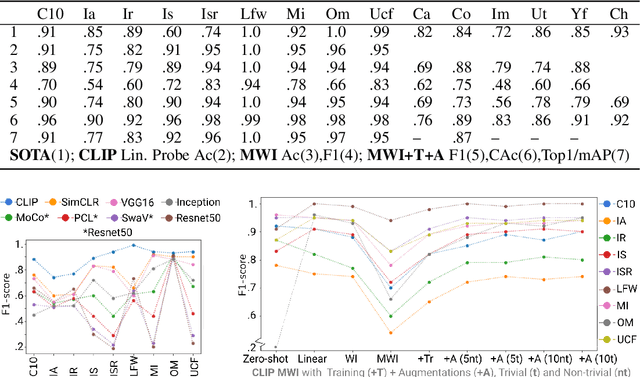
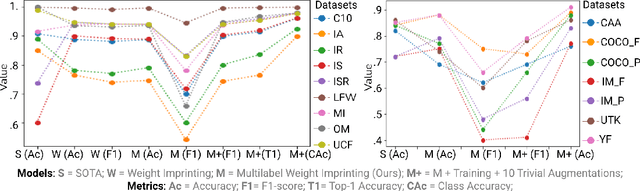
Self-supervised or weakly supervised models trained on large-scale datasets have shown sample-efficient transfer to diverse datasets in few-shot settings. We consider how upstream pretrained models can be leveraged for downstream few-shot, multilabel, and continual learning tasks. Our model CLIPPER (CLIP PERsonalized) uses image representations from CLIP, a large-scale image representation learning model trained using weak natural language supervision. We developed a technique, called Multi-label Weight Imprinting (MWI), for multi-label, continual, and few-shot learning, and CLIPPER uses MWI with image representations from CLIP. We evaluated CLIPPER on 10 single-label and 5 multi-label datasets. Our model shows robust and competitive performance, and we set new benchmarks for few-shot, multi-label, and continual learning. Our lightweight technique is also compute-efficient and enables privacy-preserving applications as the data is not sent to the upstream model for fine-tuning.