 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMTrack: End-to-End Trained Spiking Neural Networks for Multi-Object Tracking in RGB Videos
Aug 20, 2025Brain-inspired Spiking Neural Networks (SNNs) exhibit significant potential for low-power computation, yet their application in visual tasks remains largely confined to image classification, object detection, and event-based tracking. In contrast, real-world vision systems still widely use conventional RGB video streams, where the potential of directly-trained SNNs for complex temporal tasks such as multi-object tracking (MOT) remains underexplored. To address this challenge, we propose SMTrack-the first directly trained deep SNN framework for end-to-end multi-object tracking on standard RGB videos. SMTrack introduces an adaptive and scale-aware Normalized Wasserstein Distance loss (Asa-NWDLoss) to improve detection and localization performance under varying object scales and densities. Specifically, the method computes the average object size within each training batch and dynamically adjusts the normalization factor, thereby enhancing sensitivity to small objects. For the association stage, we incorporate the TrackTrack identity module to maintain robust and consistent object trajectories. Extensive evaluations on BEE24, MOT17, MOT20, and DanceTrack show that SMTrack achieves performance on par with leading ANN-based MOT methods, advancing robust and accurate SNN-based tracking in complex scenarios.
AdR-Gaussian: Accelerating Gaussian Splatting with Adaptive Radius
Sep 13, 20243D Gaussian Splatting (3DGS) is a recent explicit 3D representation that has achieved high-quality reconstruction and real-time rendering of complex scenes. However, the rasterization pipeline still suffers from unnecessary overhead resulting from avoidable serial Gaussian culling, and uneven load due to the distinct number of Gaussian to be rendered across pixels, which hinders wider promotion and application of 3DGS. In order to accelerate Gaussian splatting, we propose AdR-Gaussian, which moves part of serial culling in Render stage into the earlier Preprocess stage to enable parallel culling, employing adaptive radius to narrow the rendering pixel range for each Gaussian, and introduces a load balancing method to minimize thread waiting time during the pixel-parallel rendering. Our contributions are threefold, achieving a rendering speed of 310% while maintaining equivalent or even better quality than the state-of-the-art. Firstly, we propose to early cull Gaussian-Tile pairs of low splatting opacity based on an adaptive radius in the Gaussian-parallel Preprocess stage, which reduces the number of affected tile through the Gaussian bounding circle, thus reducing unnecessary overhead and achieving faster rendering speed. Secondly, we further propose early culling based on axis-aligned bounding box for Gaussian splatting, which achieves a more significant reduction in ineffective expenses by accurately calculating the Gaussian size in the 2D directions. Thirdly, we propose a balancing algorithm for pixel thread load, which compresses the information of heavy-load pixels to reduce thread waiting time, and enhance information of light-load pixels to hedge against rendering quality loss. Experiments on three datasets demonstrate that our algorithm can significantly improve the Gaussian Splatting rendering speed.
Multi-Object Tracking in the Dark
May 10, 2024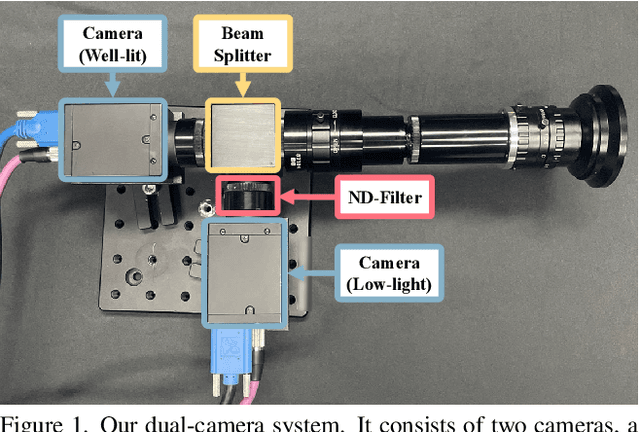
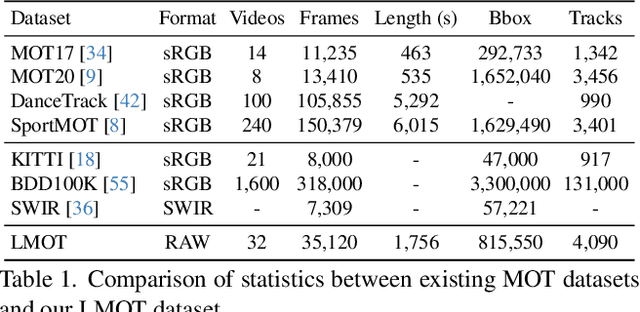

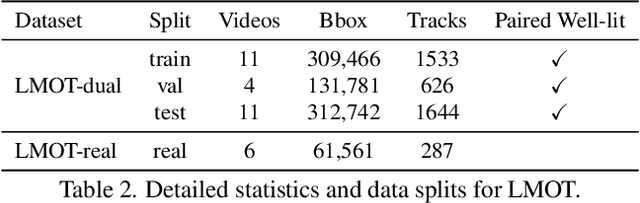
Low-light scenes are prevalent in real-world applications (e.g. autonomous driving and surveillance at night). Recently, multi-object tracking in various practical use cases have received much attention, but multi-object tracking in dark scenes is rarely considered. In this paper, we focus on multi-object tracking in dark scenes. To address the lack of datasets, we first build a Low-light Multi-Object Tracking (LMOT) dataset. LMOT provides well-aligned low-light video pairs captured by our dual-camera system, and high-quality multi-object tracking annotations for all videos. Then, we propose a low-light multi-object tracking method, termed as LTrack. We introduce the adaptive low-pass downsample module to enhance low-frequency components of images outside the sensor noises. The degradation suppression learning strategy enables the model to learn invariant information under noise disturbance and image quality degradation. These components improve the robustness of multi-object tracking in dark scenes. We conducted a comprehensive analysis of our LMOT dataset and proposed LTrack. Experimental results demonstrate the superiority of the proposed method and its competitiveness in real night low-light scenes. Dataset and Code: https: //github.com/ying-fu/LMOT
DPATD: Dual-Phase Audio Transformer for Denoising
Oct 30, 2023



Recent high-performance transformer-based speech enhancement models demonstrate that time domain methods could achieve similar performance as time-frequency domain methods. However, time-domain speech enhancement systems typically receive input audio sequences consisting of a large number of time steps, making it challenging to model extremely long sequences and train models to perform adequately. In this paper, we utilize smaller audio chunks as input to achieve efficient utilization of audio information to address the above challenges. We propose a dual-phase audio transformer for denoising (DPATD), a novel model to organize transformer layers in a deep structure to learn clean audio sequences for denoising. DPATD splits the audio input into smaller chunks, where the input length can be proportional to the square root of the original sequence length. Our memory-compressed explainable attention is efficient and converges faster compared to the frequently used self-attention module. Extensive experiments demonstrate that our model outperforms state-of-the-art methods.