 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatchscopes: A Unifying Framework for Inspecting Hidden Representations of Language Models
Paper and Code
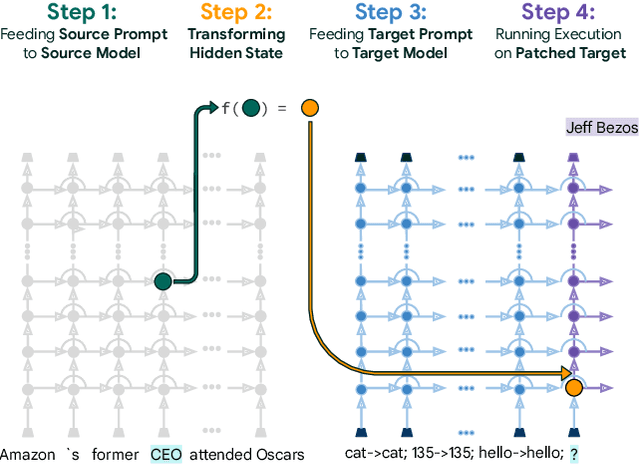
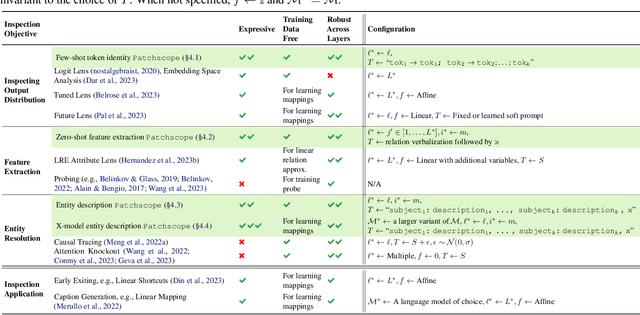
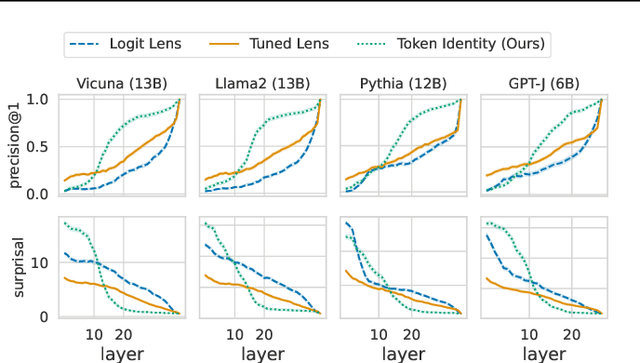
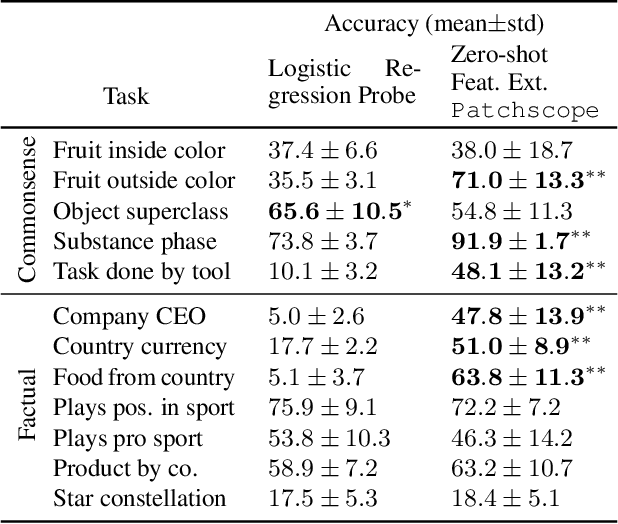
Inspecting the information encoded in hidden representations of large language models (LLMs) can explain models' behavior and verify their alignment with human values. Given the capabilities of LLMs in generating human-understandable text, we propose leveraging the model itself to explain its internal representations in natural language. We introduce a framework called Patchscopes and show how it can be used to answer a wide range of questions about an LLM's computation. We show that prior interpretability methods based on projecting representations into the vocabulary space and intervening on the LLM computation can be viewed as instances of this framework. Moreover, several of their shortcomings such as failure in inspecting early layers or lack of expressivity can be mitigated by Patchscopes. Beyond unifying prior inspection techniques, Patchscopes also opens up new possibilities such as using a more capable model to explain the representations of a smaller model, and unlocks new applications such as self-correction in multi-hop reasoning.