 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZonkey: A Hierarchical Diffusion Language Model with Differentiable Tokenization and Probabilistic Attention
Jan 29, 2026Large language models (LLMs) have revolutionized natural language processing, yet they remain constrained by fixed, non-differentiable tokenizers like Byte Pair Encoding (BPE), which hinder end-to-end optimization and adaptability to noisy or domain-specific data. We introduce Zonkey, a hierarchical diffusion model that addresses these limitations through a fully trainable pipeline from raw characters to document-level representations. At its core is a differentiable tokenizer (Segment Splitter) that learns probabilistic beginning-of-sequence (BOS) decisions, enabling adaptive splits that emerge as linguistically meaningful (e.g., word boundaries at spaces, sentence starts at periods) without explicit supervision. This differentiability is enabled by our novel Probabilistic Attention mechanism, which incorporates position-specific existence probabilities to simulate soft masking over theoretically infinite sequences while preserving gradients. Sequences decay probabilistically rather than relying on end-of-sequence tokens, supporting variable-length outputs. Hierarchical levels compress sequences into higher abstractions (e.g., character n-grams to word-like vectors, then sentence-like), with reconstruction via our Denoising Diffusion Mixed Model (DDMM) for stable and efficient denoising in latent space. A Stitcher ensures overlap invariance across segments. Trained end-to-end on Wikipedia, Zonkey generates coherent, variable-length text from noise, demonstrating emergent hierarchies and promising qualitative alignment to data distributions compared to entropy-based learnable tokenizers. Our approach advances toward fully gradient-based LLMs, with potential for better domain adaptation and scalable generation. We release the source code for training and reproducing our experiments.
Adversarial Generation and Encoding of Nested Texts
Jun 01, 2019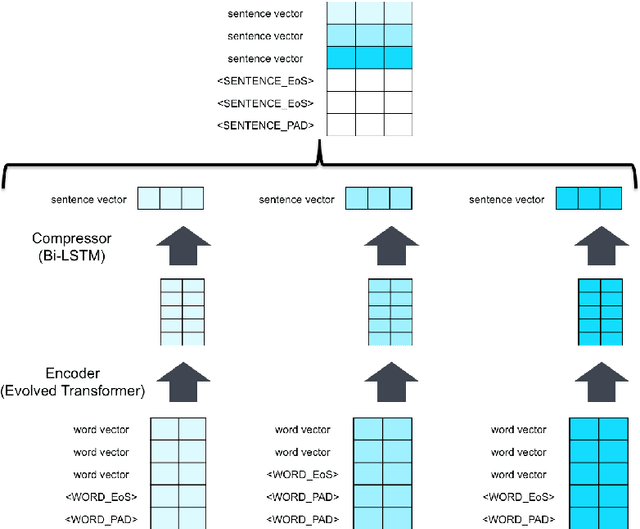

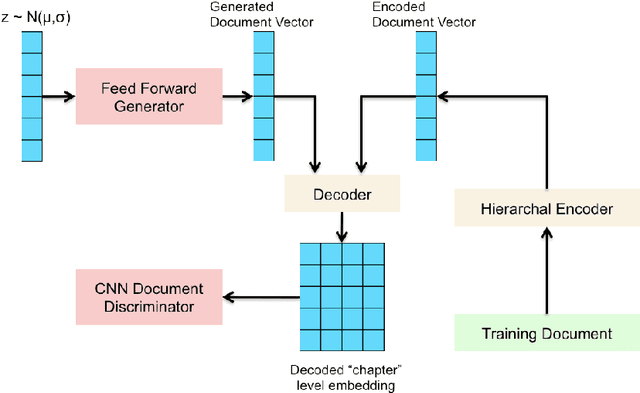
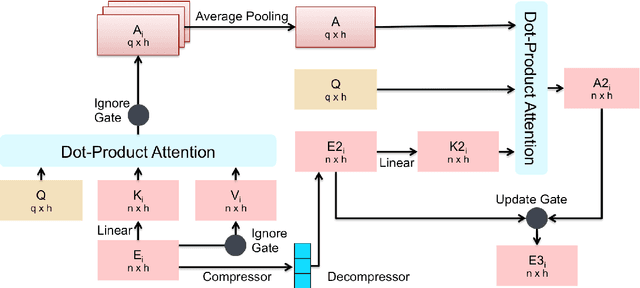
In this paper we propose a new language model called AGENT, which stands for Adversarial Generation and Encoding of Nested Texts. AGENT is designed for encoding, generating and refining documents that consist of a long and coherent text, such as an entire book, provided they are hierarchically annotated (nested). i.e. divided into sentences, paragraphs and chapters. The core idea of our system is learning vector representations for each level of the text hierarchy (sentences, paragraphs, etc...), and train each such representation to perform 3 tasks: The task of reconstructing the sequence of vectors from a lower level that was used to create the representation, and generalized versions of the Masked Language Modeling (MLM) and "Next Sentence Prediction" tasks from BERT Devlin et al. [2018]. Additionally we present a new adversarial model for long text generation and suggest a way to improve the coherence of the generated text by traversing its vector representation tree.
Latent Universal Task-Specific BERT
May 16, 2019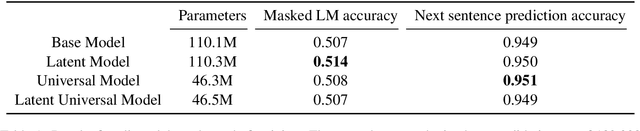
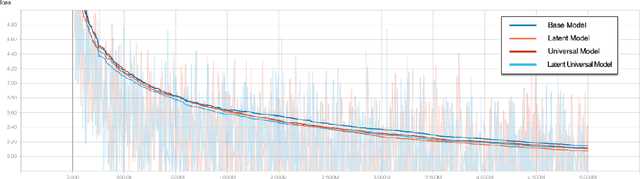
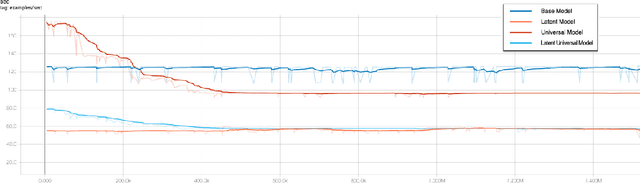
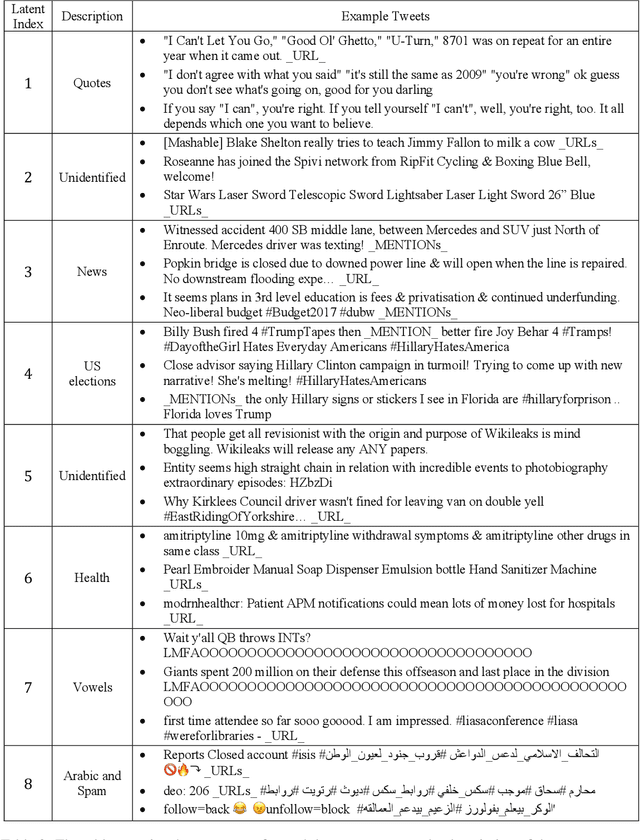
This paper describes a language representation model which combines the Bidirectional Encoder Representations from Transformers (BERT) learning mechanism described in Devlin et al. (2018) with a generalization of the Universal Transformer model described in Dehghani et al. (2018). We further improve this model by adding a latent variable that represents the persona and topics of interests of the writer for each training example. We also describe a simple method to improve the usefulness of our language representation for solving problems in a specific domain at the expense of its ability to generalize to other fields. Finally, we release a pre-trained language representation model for social texts that was trained on 100 million tweets.
Amobee at SemEval-2019 Tasks 5 and 6: Multiple Choice CNN Over Contextual Embedding
Apr 17, 2019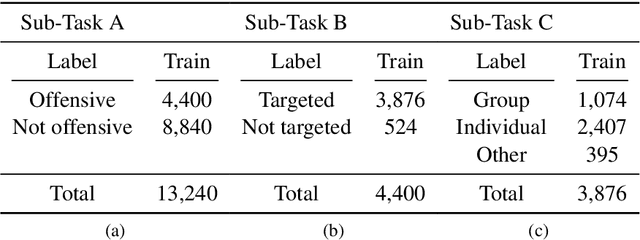
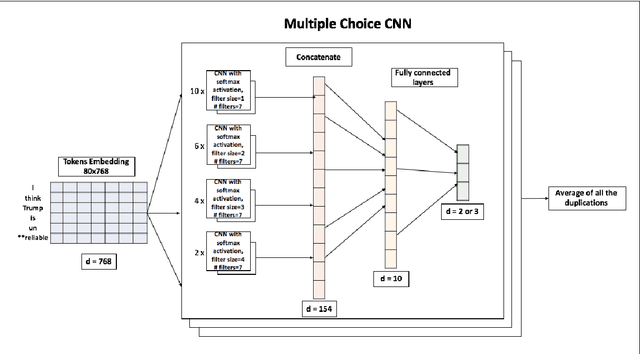
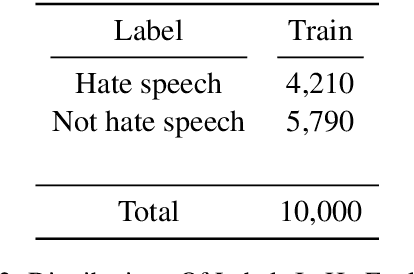
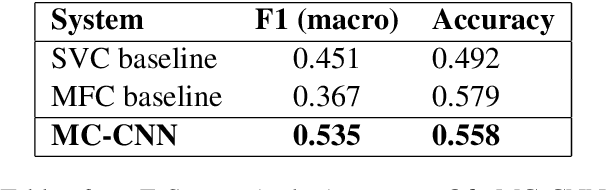
This article describes Amobee's participation in "HatEval: Multilingual detection of hate speech against immigrants and women in Twitter" (task 5) and "OffensEval: Identifying and Categorizing Offensive Language in Social Media" (task 6). The goal of task 5 was to detect hate speech targeted to women and immigrants. The goal of task 6 was to identify and categorized offensive language in social media, and identify offense target. We present a novel type of convolutional neural network called "Multiple Choice CNN" (MC-CNN) that we used over our newly developed contextual embedding, Rozental et al. (2019). For both tasks we used this architecture and achieved 4th place out of 69 participants with an F1 score of 0.53 in task 5, in task 6 achieved 2nd place (out of 75) in Sub-task B - automatic categorization of offense types (our model reached places 18/2/7 out of 103/75/65 for sub-tasks A, B and C respectively in task 6).
Amobee at IEST 2018: Transfer Learning from Language Models
Oct 23, 2018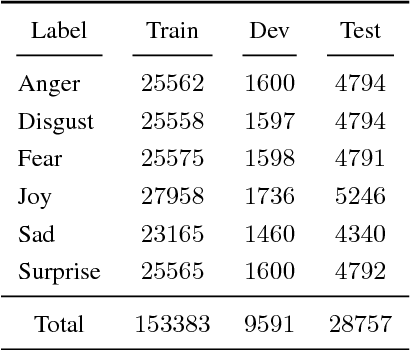
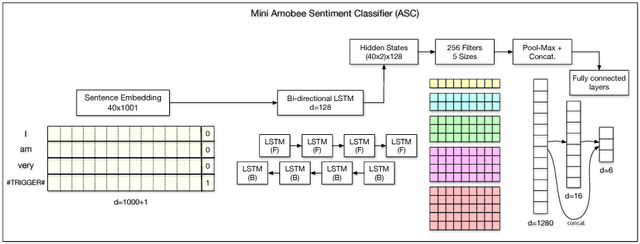
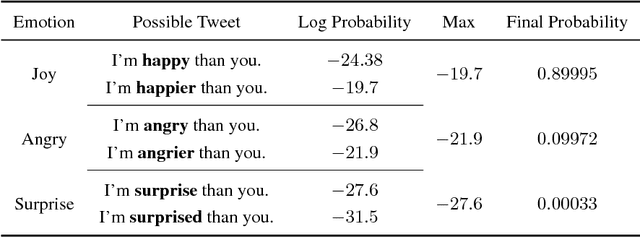
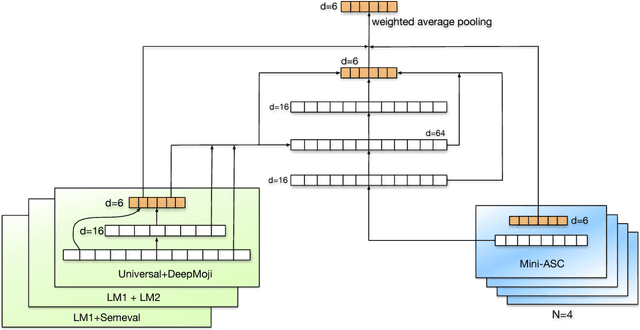
This paper describes the system developed at Amobee for the WASSA 2018 implicit emotions shared task (IEST). The goal of this task was to predict the emotion expressed by missing words in tweets without an explicit mention of those words. We developed an ensemble system consisting of language models together with LSTM-based networks containing a CNN attention mechanism. Our approach represents a novel use of language models (specifically trained on a large Twitter dataset) to predict and classify emotions. Our system reached 1st place with a macro $\text{F}_1$ score of 0.7145.
Amobee at SemEval-2018 Task 1: GRU Neural Network with a CNN Attention Mechanism for Sentiment Classification
Apr 12, 2018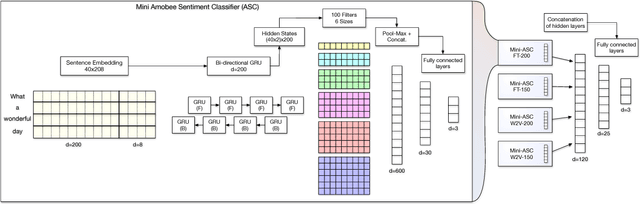

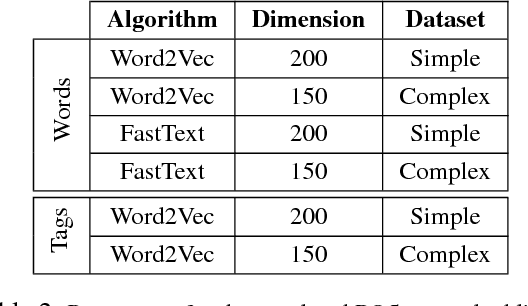
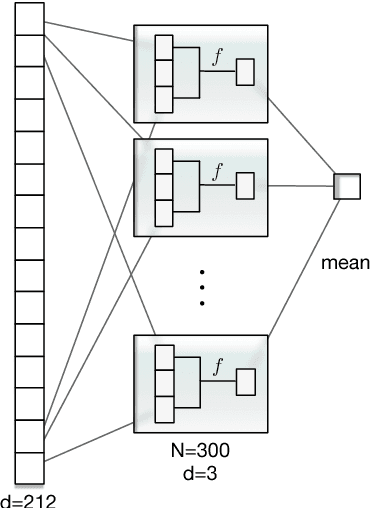
This paper describes the participation of Amobee in the shared sentiment analysis task at SemEval 2018. We participated in all the English sub-tasks and the Spanish valence tasks. Our system consists of three parts: training task-specific word embeddings, training a model consisting of gated-recurrent-units (GRU) with a convolution neural network (CNN) attention mechanism and training stacking-based ensembles for each of the sub-tasks. Our algorithm reached 3rd and 1st places in the valence ordinal classification sub-tasks in English and Spanish, respectively.
Amobee at SemEval-2017 Task 4: Deep Learning System for Sentiment Detection on Twitter
May 03, 2017

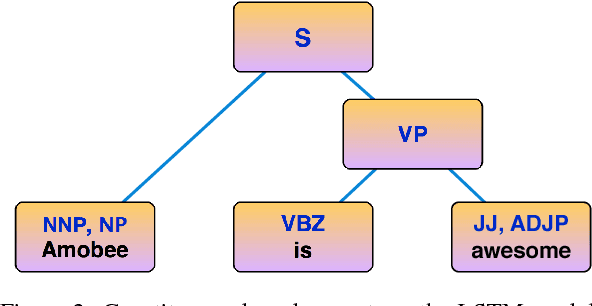
This paper describes the Amobee sentiment analysis system, adapted to compete in SemEval 2017 task 4. The system consists of two parts: a supervised training of RNN models based on a Twitter sentiment treebank, and the use of feedforward NN, Naive Bayes and logistic regression classifiers to produce predictions for the different sub-tasks. The algorithm reached the 3rd place on the 5-label classification task (sub-task C).