 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Universal Task-Specific BERT
May 16, 2019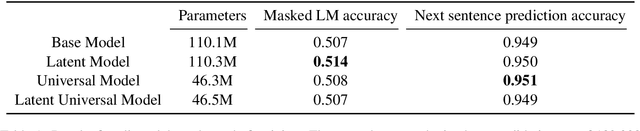
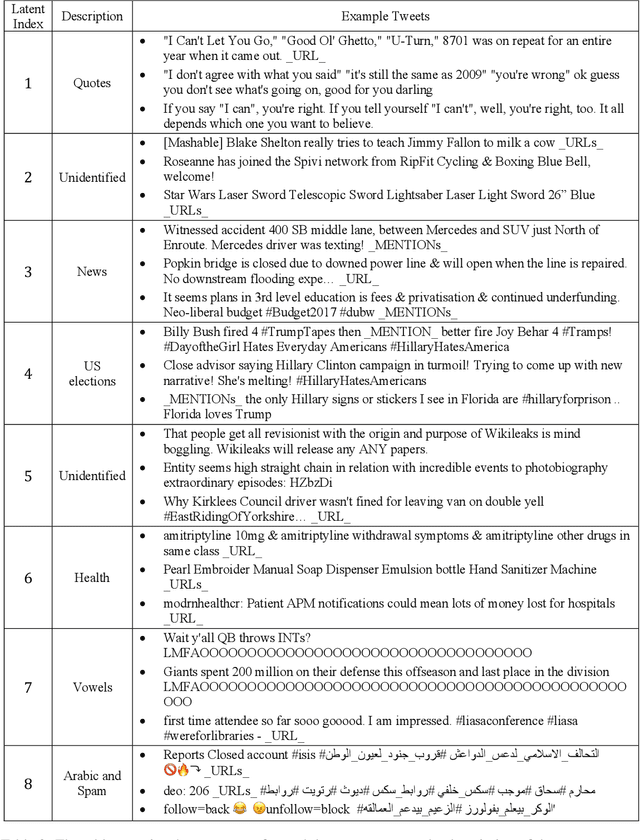
This paper describes a language representation model which combines the Bidirectional Encoder Representations from Transformers (BERT) learning mechanism described in Devlin et al. (2018) with a generalization of the Universal Transformer model described in Dehghani et al. (2018). We further improve this model by adding a latent variable that represents the persona and topics of interests of the writer for each training example. We also describe a simple method to improve the usefulness of our language representation for solving problems in a specific domain at the expense of its ability to generalize to other fields. Finally, we release a pre-trained language representation model for social texts that was trained on 100 million tweets.
Amobee at IEST 2018: Transfer Learning from Language Models
Oct 23, 2018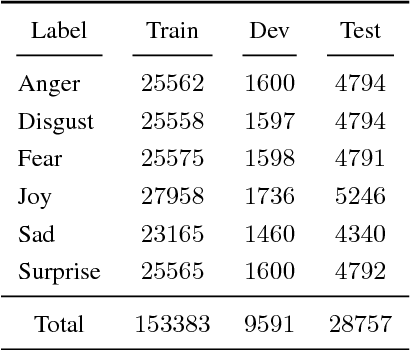
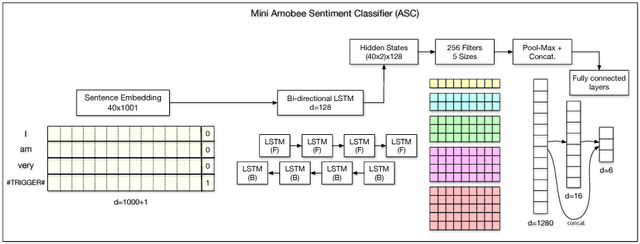
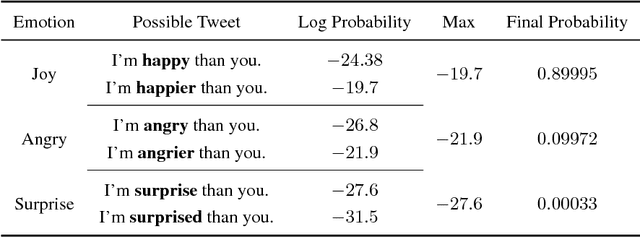
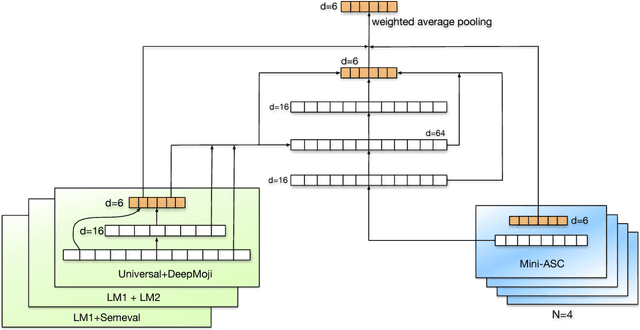
This paper describes the system developed at Amobee for the WASSA 2018 implicit emotions shared task (IEST). The goal of this task was to predict the emotion expressed by missing words in tweets without an explicit mention of those words. We developed an ensemble system consisting of language models together with LSTM-based networks containing a CNN attention mechanism. Our approach represents a novel use of language models (specifically trained on a large Twitter dataset) to predict and classify emotions. Our system reached 1st place with a macro $\text{F}_1$ score of 0.7145.