 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Much Does Attention Actually Attend? Questioning the Importance of Attention in Pretrained Transformers
Nov 07, 2022



The attention mechanism is considered the backbone of the widely-used Transformer architecture. It contextualizes the input by computing input-specific attention matrices. We find that this mechanism, while powerful and elegant, is not as important as typically thought for pretrained language models. We introduce PAPA, a new probing method that replaces the input-dependent attention matrices with constant ones -- the average attention weights over multiple inputs. We use PAPA to analyze several established pretrained Transformers on six downstream tasks. We find that without any input-dependent attention, all models achieve competitive performance -- an average relative drop of only 8% from the probing baseline. Further, little or no performance drop is observed when replacing half of the input-dependent attention matrices with constant (input-independent) ones. Interestingly, we show that better-performing models lose more from applying our method than weaker models, suggesting that the utilization of the input-dependent attention mechanism might be a factor in their success. Our results motivate research on simpler alternatives to input-dependent attention, as well as on methods for better utilization of this mechanism in the Transformer architecture.
Sentence Bottleneck Autoencoders from Transformer Language Models
Aug 31, 2021

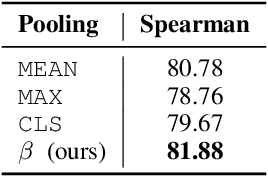

Representation learning for text via pretraining a language model on a large corpus has become a standard starting point for building NLP systems. This approach stands in contrast to autoencoders, also trained on raw text, but with the objective of learning to encode each input as a vector that allows full reconstruction. Autoencoders are attractive because of their latent space structure and generative properties. We therefore explore the construction of a sentence-level autoencoder from a pretrained, frozen transformer language model. We adapt the masked language modeling objective as a generative, denoising one, while only training a sentence bottleneck and a single-layer modified transformer decoder. We demonstrate that the sentence representations discovered by our model achieve better quality than previous methods that extract representations from pretrained transformers on text similarity tasks, style transfer (an example of controlled generation), and single-sentence classification tasks in the GLUE benchmark, while using fewer parameters than large pretrained models.
Pivot Through English: Reliably Answering Multilingual Questions without Document Retrieval
Dec 28, 2020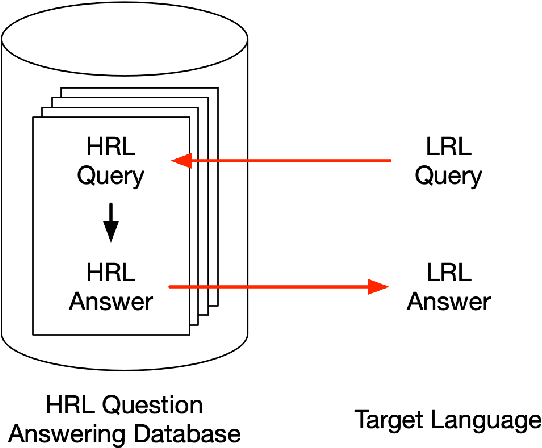

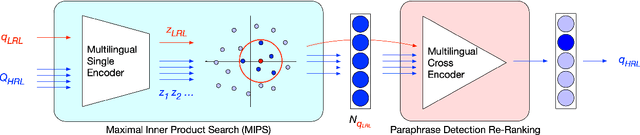
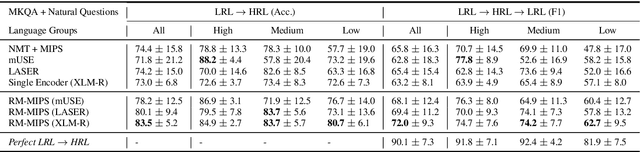
Existing methods for open-retrieval question answering in lower resource languages (LRLs) lag significantly behind English. They not only suffer from the shortcomings of non-English document retrieval, but are reliant on language-specific supervision for either the task or translation. We formulate a task setup more realistic to available resources, that circumvents document retrieval to reliably transfer knowledge from English to lower resource languages. Assuming a strong English question answering model or database, we compare and analyze methods that pivot through English: to map foreign queries to English and then English answers back to target language answers. Within this task setup we propose Reranked Multilingual Maximal Inner Product Search (RM-MIPS), akin to semantic similarity retrieval over the English training set with reranking, which outperforms the strongest baselines by 2.7% on XQuAD and 6.2% on MKQA. Analysis demonstrates the particular efficacy of this strategy over state-of-the-art alternatives in challenging settings: low-resource languages, with extensive distractor data and query distribution misalignment. Circumventing retrieval, our analysis shows this approach offers rapid answer generation to almost any language off-the-shelf, without the need for any additional training data in the target language.
Plug and Play Autoencoders for Conditional Text Generation
Oct 12, 2020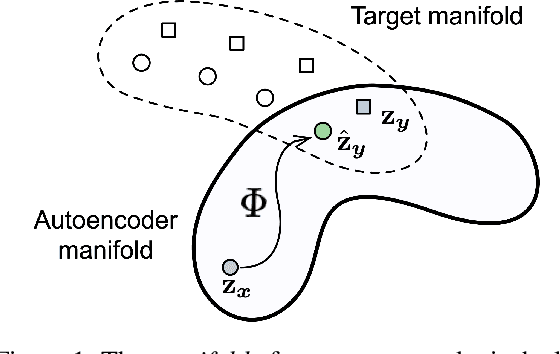


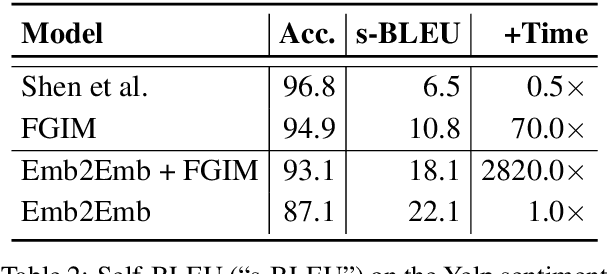
Text autoencoders are commonly used for conditional generation tasks such as style transfer. We propose methods which are plug and play, where any pretrained autoencoder can be used, and only require learning a mapping within the autoencoder's embedding space, training embedding-to-embedding (Emb2Emb). This reduces the need for labeled training data for the task and makes the training procedure more efficient. Crucial to the success of this method is a loss term for keeping the mapped embedding on the manifold of the autoencoder and a mapping which is trained to navigate the manifold by learning offset vectors. Evaluations on style transfer tasks both with and without sequence-to-sequence supervision show that our method performs better than or comparable to strong baselines while being up to four times faster.